Arquitetura Grace Blackwell e Benchmarks no DGX Spark

Desempenho e Arquitetura Grace Blackwell no NVIDIA DGX Spark
A aceleração da inteligência artificial generativa trouxe uma mudança estrutural no modo como infraestrutura computacional é projetada. Modelos de linguagem de grande escala (LLMs), sistemas multimodais e aplicações avançadas de visão computacional elevaram drasticamente os requisitos de processamento, memória e largura de banda.
Nesse contexto, arquiteturas tradicionais baseadas em CPUs e GPUs discretas passaram a enfrentar limitações práticas, principalmente quando o objetivo é executar modelos localmente. A necessidade de grandes volumes de memória, alto throughput de inferência e ferramentas de desenvolvimento integradas levou à criação de novas plataformas voltadas especificamente para IA.
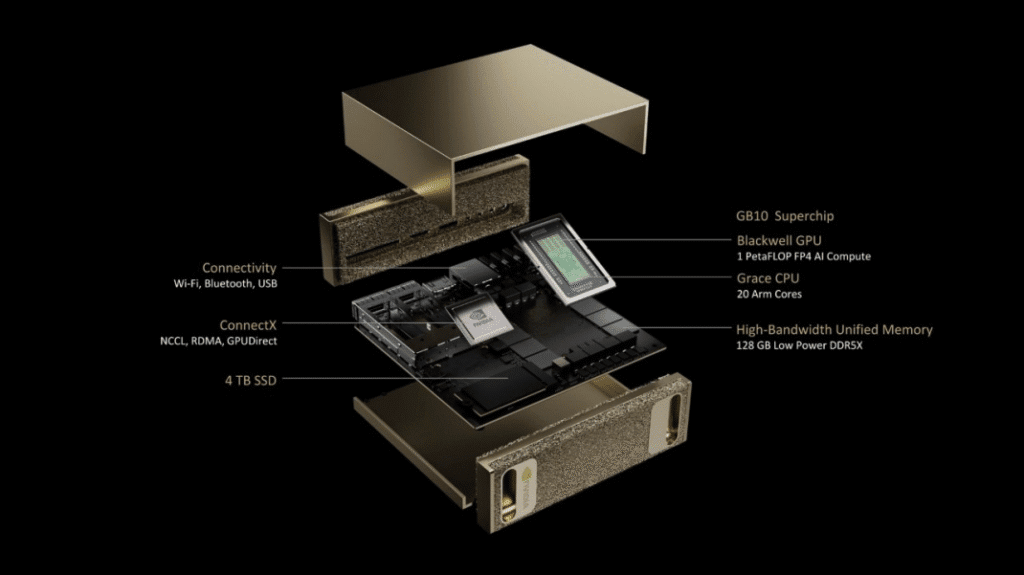
É nesse cenário que surge o NVIDIA DGX Spark, um sistema projetado para levar a experiência de supercomputação de IA para o ambiente de desktop. Equipado com o superchip NVIDIA GB10 baseado na arquitetura Grace Blackwell, o equipamento oferece até 1 petaFLOP de desempenho em IA com precisão FP4, aliado a 128 GB de memória unificada LPDDR5x e uma pilha completa de software de inteligência artificial.
Mais do que apenas um hardware potente, o DGX Spark representa uma mudança no paradigma de desenvolvimento de IA. Em vez de depender exclusivamente de data centers ou serviços em nuvem, pesquisadores e desenvolvedores podem prototipar, ajustar e executar modelos de até 200 bilhões de parâmetros localmente.
Neste artigo, analisaremos em profundidade os fundamentos técnicos da arquitetura Grace Blackwell, os diferenciais do superchip GB10 e como essas tecnologias impactam diretamente o desempenho em workloads modernos de IA, incluindo LLMs, aplicações multimodais e pipelines de inferência.
O Desafio da Infraestrutura para IA Generativa
A rápida evolução dos modelos de IA generativa criou uma nova categoria de demanda computacional. Modelos com dezenas ou centenas de bilhões de parâmetros exigem quantidades significativas de memória e processamento paralelo para executar inferências em tempo aceitável.
Tradicionalmente, essas cargas de trabalho eram executadas em clusters de GPUs em data centers especializados. Embora esse modelo ofereça alto desempenho, ele apresenta desafios importantes para organizações e desenvolvedores individuais.
Limitações das GPUs tradicionais
Mesmo GPUs de alto desempenho possuem limitações quando utilizadas para modelos muito grandes. Um exemplo citado frequentemente é o fato de que uma GPU moderna pode ter apenas algumas dezenas de gigabytes de memória dedicada.
Quando modelos de linguagem aumentam seu contexto ou número de parâmetros, esse limite é rapidamente atingido. Isso obriga o uso de técnicas como divisão de modelos entre múltiplas GPUs ou utilização de memória do sistema, aumentando a latência e complexidade operacional.
Além disso, plataformas convencionais de desktop raramente ultrapassam 32 GB de memória RAM, tornando praticamente inviável executar modelos avançados localmente sem infraestrutura especializada.
Impacto no desenvolvimento de IA
Essa limitação não afeta apenas o desempenho de inferência. Atividades fundamentais do ciclo de desenvolvimento de IA, como ajuste fino de modelos, testes experimentais e prototipagem, também se tornam dependentes de ambientes remotos.
Como consequência, desenvolvedores enfrentam custos operacionais elevados e dependência de infraestrutura externa. O resultado é um ciclo de inovação mais lento e menos flexível.
O DGX Spark foi concebido justamente para reduzir essa lacuna entre desenvolvimento local e infraestrutura de data center.
[IMAGEM 2 – Comparação entre infraestrutura tradicional de IA e computação local com DGX Spark]
Fundamentos da Arquitetura Grace Blackwell
No coração do DGX Spark está o superchip NVIDIA GB10, construído sobre a arquitetura Grace Blackwell. Essa arquitetura representa uma abordagem diferente da computação acelerada tradicional, integrando CPU e GPU em um único pacote altamente otimizado.
Integração de CPU ARM e GPU Blackwell
O GB10 combina um complexo de CPUs ARM com uma GPU baseada na arquitetura Blackwell. Ambos os componentes são fabricados em processo de 3 nanômetros e conectados por meio do interconector NVLink C2C de alta largura de banda.
Essa integração permite que CPU e GPU compartilhem memória de forma coerente, eliminando muitas das barreiras tradicionais entre processamento geral e processamento acelerado.
Em ambientes de IA, essa característica é particularmente relevante, pois reduz a necessidade de cópias de dados entre dispositivos, um dos fatores que mais contribuem para aumento de latência.
Memória unificada de 128 GB
Outro elemento central da arquitetura é o uso de 128 GB de memória LPDDR5x unificada. Diferentemente de arquiteturas tradicionais que separam memória do sistema e VRAM da GPU, o DGX Spark utiliza um único pool compartilhado.
Essa memória opera com interface de 256 bits e largura de banda de aproximadamente 273 GB/s. Embora não seja tão alta quanto a de GPUs com memória GDDR dedicada, a grande capacidade permite executar modelos muito maiores localmente.
Na prática, isso significa que modelos que exigiriam múltiplas GPUs podem ser carregados diretamente no sistema, simplificando significativamente o desenvolvimento e testes.
Precisão FP4 e o Novo Paradigma de Inferência
Um dos diferenciais técnicos mais importantes da arquitetura Grace Blackwell é o suporte ao formato de precisão FP4, projetado especificamente para cargas de trabalho de inferência em IA.
Tradicionalmente, operações de aprendizado profundo utilizam precisão FP32 ou FP16. Embora essas representações garantam alta fidelidade numérica, elas consomem grandes quantidades de memória e largura de banda.
Redução de precisão para aumentar eficiência
O formato FP4 reduz drasticamente a quantidade de dados necessária para representar parâmetros de um modelo. Isso permite que modelos muito maiores sejam executados dentro do mesmo espaço de memória.
No DGX Spark, essa abordagem possibilita alcançar até 1 petaFLOP de desempenho de IA em operações FP4. A utilização de esparsidade e quantização permite manter qualidade aceitável ao mesmo tempo em que reduz a pressão sobre a memória.
Esse conceito é particularmente relevante para inferência em LLMs, onde grande parte do custo computacional está associada à movimentação de dados.
Impacto na execução de modelos de grande escala
Combinando memória unificada de grande capacidade e precisão FP4, o DGX Spark pode executar modelos de até 200 bilhões de parâmetros localmente.
Isso representa um salto significativo em relação a plataformas tradicionais de desktop, onde modelos com dezenas de bilhões de parâmetros frequentemente excedem a capacidade disponível.
Benchmarks de IA e Desempenho Real
Benchmarks realizados com workloads de linguagem natural demonstram claramente o comportamento da arquitetura em cenários reais.
Throughput em processamento de prompts
Durante a fase inicial de processamento de prompts, conhecida como prefill, o DGX Spark demonstra desempenho elevado graças à capacidade computacional da GPU Blackwell e ao uso de precisão reduzida.
Em testes com modelos de grande escala, o sistema alcançou taxas superiores a 1.700 tokens por segundo nessa etapa.
Esse desempenho é resultado direto da capacidade do hardware de executar operações de matriz em larga escala com alta eficiência.
Latência na geração de tokens
Na fase de geração de tokens, conhecida como decode, o comportamento muda. Essa etapa depende fortemente da largura de banda da memória, e não apenas do poder de processamento.
Com largura de banda de aproximadamente 273 GB/s, o DGX Spark apresenta taxas de geração de cerca de 38 tokens por segundo em determinados cenários.
Embora inferior a sistemas com múltiplas GPUs dedicadas, o resultado ainda permite execução local de modelos que normalmente exigiriam infraestrutura muito maior.
Escalabilidade com Conectividade NVIDIA ConnectX
Outro elemento estratégico do DGX Spark é a possibilidade de expansão por meio da rede NVIDIA ConnectX.
O sistema inclui uma NIC ConnectX-7 Smart NIC capaz de fornecer até 100 gigabits Ethernet, permitindo interconectar múltiplos sistemas.
Cluster de dois DGX Spark
Ao conectar dois sistemas DGX Spark, é possível trabalhar com modelos de até 405 bilhões de parâmetros. Esse tipo de configuração cria um pequeno cluster de IA capaz de distribuir tarefas entre dispositivos.
Esse recurso permite ampliar gradualmente a infraestrutura de desenvolvimento sem necessidade de migrar imediatamente para um data center completo.
Integração com bibliotecas distribuídas
Bibliotecas como NCCL permitem que workloads distribuídos sejam executados entre múltiplos nós. Isso abre caminho para experimentos com computação distribuída diretamente em ambientes de desenvolvimento.
Ecossistema de Software NVIDIA para IA
Além da arquitetura de hardware, o DGX Spark inclui a pilha completa de software de IA da NVIDIA.
Isso inclui frameworks, bibliotecas e ferramentas otimizadas para desenvolvimento e implantação de modelos de aprendizado profundo.
DGX OS e ambiente de desenvolvimento
O sistema operacional DGX OS fornece um ambiente baseado em Linux com suporte nativo para frameworks populares de IA.
Ferramentas como CUDA, bibliotecas de deep learning e containers prontos para execução permitem iniciar projetos rapidamente.
Suporte a frameworks e modelos
A plataforma é projetada para trabalhar com modelos desenvolvidos por organizações como DeepSeek, Meta, Google, NVIDIA e outras.
Isso garante compatibilidade com grande parte do ecossistema atual de IA generativa.
Aplicações em Workloads de IA
O DGX Spark foi projetado para suportar uma variedade de workloads relacionados ao desenvolvimento de inteligência artificial.
Prototipagem e experimentação
Desenvolvedores podem utilizar o sistema para criar protótipos de aplicações de IA, validar modelos e testar pipelines de inferência.
Essa etapa é essencial para avaliar desempenho e comportamento antes da implantação em ambientes de produção.
Fine-tuning de modelos
O sistema também pode ser utilizado para ajustes finos de modelos com até 70 bilhões de parâmetros, permitindo personalização para domínios específicos.
Inferência em produção experimental
Em ambientes de pesquisa ou edge computing, o DGX Spark pode atuar como plataforma de inferência local para aplicações de IA.
Medição de Sucesso e Métricas de Avaliação
A avaliação do desempenho de sistemas de IA não se limita apenas a FLOPS ou throughput bruto.
Outras métricas importantes incluem latência de inferência, eficiência energética e capacidade de executar modelos de grande escala.
No caso do DGX Spark, a principal métrica de sucesso é a capacidade de executar localmente modelos que antes exigiam infraestrutura distribuída.
Conclusão
A arquitetura Grace Blackwell introduzida no NVIDIA DGX Spark representa uma mudança significativa na forma como sistemas de IA são projetados para ambientes de desenvolvimento.
Ao integrar CPU ARM, GPU Blackwell, memória unificada de grande capacidade e suporte a precisão FP4, o sistema cria uma plataforma capaz de executar modelos extremamente grandes diretamente no desktop.
Embora não substitua clusters de GPUs dedicadas em termos de throughput bruto, o DGX Spark oferece uma combinação única de capacidade, integração e facilidade de uso.
Para desenvolvedores, pesquisadores e cientistas de dados, isso significa acesso a um ambiente completo de experimentação em IA sem dependência imediata de infraestrutura de data center.
À medida que modelos continuam a crescer em complexidade e tamanho, plataformas como o DGX Spark podem desempenhar um papel importante na democratização do desenvolvimento de inteligência artificial avançada.

