


SuperServer 4U Dual-Root PCIe: Desempenho Máximo em HPC e IA
O SuperServer 4U Dual-Root PCIe representa uma solução de ponta para organizações que demandam alto desempenho computacional em ambientes de High Performance Computing (HPC), IA/Deep Learning, automação industrial, análise de dados e modelagem financeira. Com suporte para até 8 GPUs de 600W, memória DDR5 ECC de alta velocidade e armazenamento NVMe ultrarrápido, este sistema oferece uma infraestrutura robusta para cargas críticas, garantindo performance, escalabilidade e confiabilidade.
Introdução: Contextualização Estratégica
No cenário atual, empresas e centros de pesquisa enfrentam uma pressão crescente para processar volumes massivos de dados em tempo reduzido. Áreas como inteligência artificial, análise de grandes bases de dados e simulações complexas dependem de soluções de computação que combinem alta capacidade de processamento, interconectividade eficiente entre CPU e GPU e armazenamento de baixa latência. A escolha de servidores que atendam a esses requisitos é estratégica, pois impacta diretamente no tempo de entrega de projetos, custo operacional e vantagem competitiva.
Um desafio crítico é a integração de múltiplas GPUs de alto consumo energético sem comprometer a estabilidade do sistema ou a performance do barramento PCIe. A implementação inadequada pode resultar em throttling, gargalos de comunicação entre CPU e GPU e indisponibilidade para workloads sensíveis a tempo de execução, como treinamento de modelos de IA e processamento financeiro em tempo real.
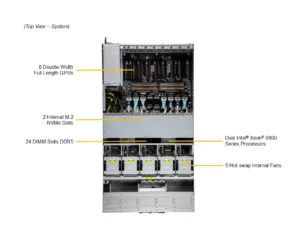
O SuperServer SYS-422GL-NR da Supermicro aborda esses desafios por meio de arquitetura Dual-Root PCIe, suporte a até 8 GPUs de 600W e interconexão NVIDIA NVLink opcional, garantindo throughput elevado e escalabilidade para workloads críticos.
Problema Estratégico: Desafios de HPC e IA em Infraestruturas Tradicionais
Capacidade de Processamento Limitada
Servidores convencionais muitas vezes não suportam múltiplas GPUs de alta potência, limitando a capacidade de treinamento de modelos complexos de IA. Isso impacta diretamente prazos de projeto e qualidade das análises, pois o paralelismo massivo necessário não pode ser plenamente explorado.
Gargalos de Interconexão
Em sistemas tradicionais, a comunicação entre CPU e GPU pode se tornar um gargalo crítico. O SuperServer utiliza arquitetura Dual-Root PCIe 5.0 x16 para cada CPU, permitindo máxima largura de banda dedicada às GPUs e reduzindo latência de comunicação, essencial para operações de deep learning distribuído e simulações financeiras em tempo real.
Limitações de Memória e Armazenamento
Workloads intensivos em dados exigem memória de alta capacidade e consistência de erros (ECC) para prevenir falhas críticas. Este servidor suporta até 24 DIMMs DDR5 ECC de até 6400 MT/s (ou 8800 MT/s MRDIMM), totalizando até 6TB por CPU, além de até 8 NVMe E1.S hot-swap de alta velocidade, permitindo armazenamento rápido para datasets massivos.

Consequências da Inação: Custos e Riscos
A escolha de servidores inadequados para HPC ou IA pode gerar impactos severos:
- Perda de competitividade: lentidão em treinamento de modelos de IA ou análise de dados frente a concorrentes com infraestrutura otimizada.
- Custos operacionais elevados: maior consumo energético devido a sistemas menos eficientes e maior tempo de processamento.
- Riscos de falha: memória não ECC ou barramentos insuficientes podem gerar erros silenciosos em cálculos críticos.
- Escalabilidade limitada: dificuldade de expandir capacidade GPU ou memória sem substituição de toda a plataforma.
Fundamentos da Solução: Arquitetura e Recursos Técnicos
CPU Dual Socket Intel Xeon 6900
O sistema utiliza dois processadores Intel Xeon série 6900 com P-cores de até 500W, permitindo 72 núcleos e 144 threads combinadas. Essa configuração garante processamento paralelo massivo e suporte a interconexão de alta largura de banda com GPUs, essencial para operações de HPC e IA. O suporte a TDP elevado permite utilizar CPUs de ponta sem throttling, garantindo estabilidade mesmo sob carga máxima.
GPU e Interconexão
Até 8 GPUs de 600W podem ser instaladas, incluindo NVIDIA H100 NVL, H200 NVL (141GB) e RTX PRO 6000 Blackwell. Para cargas de IA distribuídas, o uso opcional de NVIDIA NVLink entre GPUs reduz latência de comunicação, permitindo treinamento de modelos com datasets enormes e complexos sem gargalos. A arquitetura Dual-Root PCIe 5.0 x16 oferece caminhos dedicados para GPUs, evitando saturação do barramento.
Memória e Armazenamento
O servidor suporta até 24 DIMMs DDR5 ECC RDIMM ou MRDIMM, com taxas de até 6400/8800 MT/s, permitindo consistência e alta performance. O armazenamento inclui até 8 E1.S NVMe hot-swap na frente, além de slots M.2 PCIe 4.0, garantindo flexibilidade para configuração de datasets locais e cache de alto desempenho. A memória ECC protege contra erros silenciosos, crucial para aplicações científicas e financeiras.
Redundância e Segurança
Quatro fontes redundantes de 3200W (configuração 3+1) nível Titanium garantem operação contínua, mesmo em caso de falha de uma unidade. Segurança é reforçada por TPM 2.0, Silicon Root of Trust (NIST 800-193) e firmware assinado, assegurando integridade do sistema, proteção de dados e compliance em ambientes regulados.

Implementação Estratégica: Otimizando HPC e IA
Configuração Modular
O SuperServer permite flexibilidade de expansão via slots PCIe adicionais e hot-swap NVMe, facilitando upgrades sem downtime. Estratégias de balanceamento de carga entre CPUs e GPUs maximizam utilização de recursos, essencial para treinamento paralelo em IA ou simulações financeiras de alta complexidade.
Gerenciamento Avançado
Ferramentas como SuperCloud Composer, Supermicro Server Manager e Thin-Agent Service permitem monitoramento, provisionamento e automação, reduzindo esforço operacional e aumentando confiabilidade em centros de dados críticos. Recursos de diagnóstico offline permitem identificar falhas antes que impactem workloads.
Melhores Práticas Avançadas
Otimização de GPU e CPU
Para workloads distribuídos, utilize NVLink entre GPUs quando disponível e configure perfis de energia das CPUs para maximizar throughput sem comprometer estabilidade. Monitoramento contínuo de TDP e temperatura dos componentes é essencial para prevenir throttling em cargas prolongadas.
Gestão de Memória e Armazenamento
Use configurações balanceadas de memória (1DPC vs 2DPC) conforme a necessidade de performance vs capacidade. Armazenamento NVMe deve ser configurado com RAID ou software-defined storage para garantir redundância e throughput adequado, especialmente em análises financeiras ou simulações científicas que exigem latência mínima.
Segurança e Compliance
Implemente Secure Boot, criptografia de firmware e monitoramento de supply chain. A integração de TPM 2.0 com políticas corporativas garante compliance em ambientes regulados, como finanças, saúde e pesquisa farmacêutica.
Medição de Sucesso
Métricas essenciais incluem:
- Utilização de CPU/GPU (%) em workloads críticos
- Throughput de memória e armazenamento (GB/s)
- Latência em treinamento de modelos IA distribuídos
- Tempo de recuperação de falhas e disponibilidade (uptime)
- Eficiência energética (% de consumo vs performance)
Indicadores de sucesso devem ser monitorados em dashboards integrados com ferramentas de gerenciamento Supermicro para garantir que a infraestrutura entregue performance consistente e confiável.
Conclusão
O SuperServer 4U Dual-Root PCIe SYS-422GL-NR representa uma solução de alto impacto estratégico para organizações que demandam HPC, IA e análise de dados em larga escala. Sua arquitetura de ponta, com suporte a múltiplas GPUs de 600W, memória DDR5 ECC de até 6TB e armazenamento NVMe rápido, assegura máxima performance, confiabilidade e escalabilidade.
Ao adotar essa plataforma, empresas mitigam riscos de falhas, aumentam throughput de processamento e garantem competitividade em setores críticos, como saúde, finanças, indústria e pesquisa científica. Perspectivas futuras indicam crescente necessidade de interconectividade GPU-CPU eficiente e armazenamento ultrarrápido, áreas em que o SuperServer já oferece soluções preparadas.
Próximos passos incluem planejamento de configuração específica para workloads, implementação de políticas de segurança e monitoramento contínuo de métricas de desempenho, garantindo que a infraestrutura suporte crescimento de demanda e inovação tecnológica.


















