


Introdução: Computação Acelerada em Escala Corporativa
A transformação digital nas empresas atingiu um ponto em que a capacidade de processamento paralelo se tornou o alicerce da inovação. Modelos de IA generativa, simulações científicas complexas e treinamento de redes neurais profundas exigem infraestrutura capaz de lidar com volumes massivos de dados e processamento intensivo em GPU.
Nesse contexto, o Servidor GPU 10U da Supermicro com NVIDIA HGX B200 e processadores AMD EPYC 9005/9004 representa o ápice da engenharia em computação de alto desempenho (HPC). Projetado para operações críticas em data centers corporativos e ambientes científicos, esse sistema entrega densidade computacional extrema, eficiência energética de classe Titanium e integração arquitetônica otimizada entre CPU, GPU, memória e rede.

O artigo a seguir examina em profundidade como o design 10U com 8 GPUs NVIDIA B200 SXM e arquitetura AMD EPYC cria uma plataforma robusta para IA, aprendizado profundo e cargas de trabalho científicas avançadas — explorando fundamentos técnicos, desafios de implementação e implicações estratégicas para o negócio.

O Problema Estratégico: Limites da Computação Convencional
O avanço de modelos de IA com centenas de bilhões de parâmetros e simulações científicas de alta fidelidade impõe uma limitação clara às arquiteturas tradicionais baseadas apenas em CPU. Mesmo processadores de última geração atingem gargalos quando a tarefa exige milhares de operações matriciais simultâneas e grande largura de banda de memória.
Empresas em setores como pesquisa científica, automação industrial, saúde e finanças enfrentam o dilema de escalar desempenho sem comprometer eficiência energética e custo operacional. A infraestrutura convencional não oferece interconexão de baixa latência entre múltiplas GPUs nem suporte a memória DDR5 de alta frequência com correção ECC.
É nesse cenário que o sistema 10U com NVIDIA HGX B200 8-GPU redefine os limites, permitindo um salto quântico em paralelismo computacional e throughput. Ele oferece uma base sólida para projetos de IA corporativa e HPC, com confiabilidade e previsibilidade de desempenho.
Consequências da Inação: Gargalos e Perda de Competitividade
Ignorar a transição para plataformas aceleradas por GPU pode gerar consequências estratégicas severas. Modelos de aprendizado profundo demoram dias ou semanas para treinar em sistemas apenas com CPU, reduzindo a velocidade de inovação. Projetos científicos que exigem análise de dados climáticos, genômicos ou financeiros em tempo real tornam-se inviáveis.
Além disso, há implicações diretas no custo de oportunidade. A incapacidade de processar grandes volumes de dados rapidamente impacta a tomada de decisão baseada em IA, reduzindo a vantagem competitiva em mercados altamente dinâmicos.
O Servidor GPU 10U da Supermicro responde a esses desafios ao combinar 8 GPUs NVIDIA HGX B200 (180GB) com interconexão NVLink e NVSwitch, criando um tecido de comunicação interna de baixa latência e alta largura de banda. Esse design elimina gargalos típicos e maximiza o uso simultâneo dos recursos de GPU.
Fundamentos da Solução: Arquitetura Integrada AMD + NVIDIA
Processamento Híbrido de Alta Densidade
O sistema adota duas CPUs AMD EPYC™ das séries 9005/9004, oferecendo até 384 núcleos e 768 threads, com suporte a 500W TDP por CPU. Essa configuração garante distribuição balanceada de threads e largura de banda PCIe 5.0 x16, essencial para comunicação direta CPU-GPU.
Cada GPU NVIDIA B200 se beneficia de NVLink e NVSwitch, formando uma malha de interconexão que permite transferência massiva de dados entre GPUs sem intervenção da CPU. Isso é vital em workloads de IA e HPC, onde a sincronização entre GPUs define o tempo total de execução.
Memória DDR5 ECC de Alta Velocidade
Com 24 slots DIMM e suporte a até 6TB de memória DDR5 ECC RDIMM 6400 MT/s, o sistema oferece uma plataforma ideal para aplicações que demandam latência mínima e integridade total dos dados. O suporte ECC é fundamental em ambientes científicos e financeiros, onde erros de bit podem comprometer resultados e decisões.
Eficiência Energética e Resiliência de Data Center
O sistema conta com seis fontes redundantes de 5250W certificadas Titanium (96%), assegurando operação contínua com redução de consumo elétrico em larga escala. Essa eficiência é crucial para data centers corporativos, onde cada watt economizado se traduz em menor custo operacional e menor impacto ambiental.
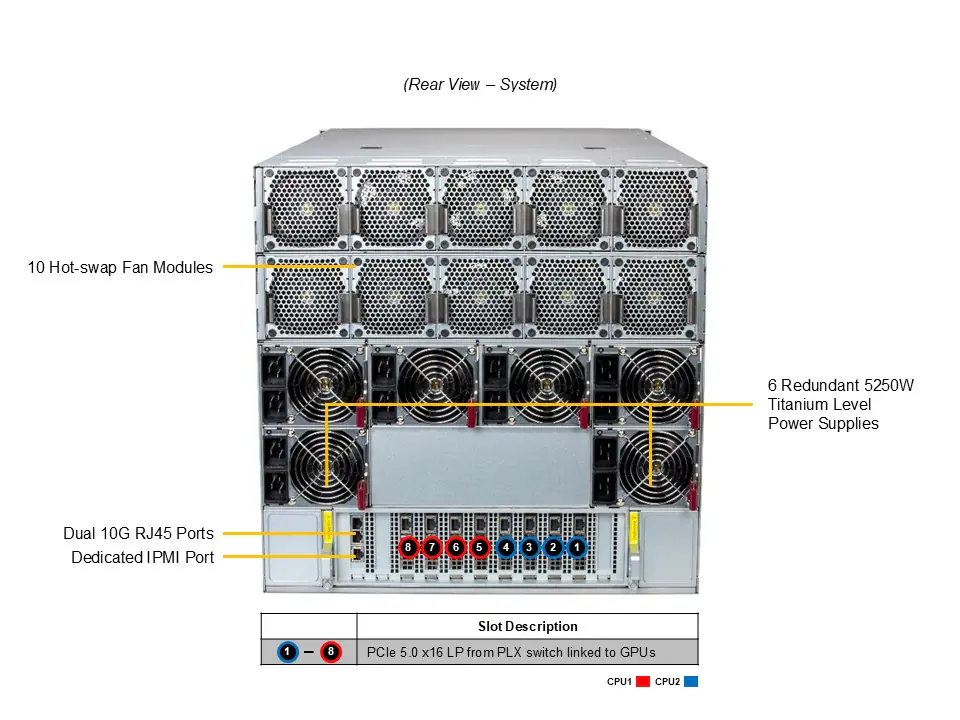
Implementação Estratégica: Desenho e Operação em Escala
Infraestrutura Física e Térmica
Com formato 10U e peso líquido de 133 kg, o servidor requer racks de alta capacidade estrutural e planejamento térmico rigoroso. O sistema inclui até 19 ventoinhas de 8 cm com controle PWM, otimizando a refrigeração de GPUs SXM de alto consumo.
A implementação em data centers exige monitoramento contínuo de temperatura, voltagem e fluxo de ar, funções integradas via SuperDoctor® 5 e BMC com suporte a ACPI e System Lockdown. Essa abordagem garante estabilidade operacional sob cargas extremas.
Gerenciamento e Automação Avançada
A integração com o ecossistema Supermicro SuperCloud Composer®, SSM, SUM e SAA simplifica a administração em larga escala. O SuperServer Automation Assistant (SAA) permite provisionamento automatizado, reduzindo tempo de configuração e erros humanos — fator crítico em ambientes com dezenas de nós GPU interligados.
Segurança de Firmware e Supply Chain
O sistema inclui TPM 2.0, Secure Boot, Firmware Assinado e Recuperação Automática, além de Remote Attestation — elementos que fortalecem a segurança da cadeia de fornecimento, essencial em projetos governamentais e de pesquisa sensível.
Esses mecanismos protegem o ambiente contra manipulações de firmware, ataques persistentes e alterações não autorizadas no BIOS ou BMC.
Melhores Práticas Avançadas de Operação e Otimização
A eficiência do Servidor GPU 10U com HGX B200 depende de uma integração cuidadosa entre hardware, software e rede. A seguir, abordam-se práticas fundamentais para maximizar desempenho e longevidade do sistema:
1. Balanceamento de Carga entre CPU e GPU
Aplicações de IA devem aproveitar bibliotecas otimizadas para CUDA e cuDNN, garantindo que o processamento intensivo seja distribuído dinamicamente entre CPU e GPU. A arquitetura PCIe 5.0 x16 elimina gargalos de comunicação, mas requer tunning cuidadoso para evitar saturação de memória.
2. Escalabilidade Horizontal e Clustering
Ao integrar múltiplos nós 10U via NVIDIA NVLink Switch e rede 10GbE Intel X710, é possível formar clusters para treinamento de modelos de IA distribuídos, alcançando escalabilidade quase linear. A interconectividade robusta reduz latência de sincronização e melhora o desempenho agregado.
3. Monitoramento Contínuo e Manutenção Preditiva
O uso do SuperDoctor 5 em conjunto com telemetria via Thin-Agent Service (TAS) possibilita a análise contínua de parâmetros térmicos e de potência, prevenindo falhas antes que causem interrupções. Isso prolonga a vida útil dos componentes e mantém a confiabilidade em ambientes de missão crítica.
Medição de Sucesso: Desempenho, Eficiência e Confiabilidade
Para avaliar o sucesso de uma implementação baseada no Servidor GPU 10U da Supermicro, três métricas principais devem ser observadas:
Performance Computacional Sustentada (TFLOPS/Watt): mede eficiência energética em cargas de IA e HPC.
Tempo de Treinamento de Modelos: redução percentual no tempo total comparado a plataformas CPU-only.
Disponibilidade Operacional (Uptime): garantida pela redundância 3+3 de fontes Titanium e monitoramento automatizado.
O equilíbrio entre esses fatores define o verdadeiro retorno sobre investimento — não apenas em potência bruta, mas em eficiência, confiabilidade e previsibilidade operacional.
Conclusão: A Nova Fronteira do Desempenho Acelerado
O Servidor GPU 10U com NVIDIA HGX B200 da Supermicro estabelece um novo padrão de computação acelerada corporativa. Sua arquitetura integrada AMD + NVIDIA entrega o equilíbrio ideal entre densidade computacional, eficiência térmica e segurança de firmware, atendendo às demandas de IA generativa, HPC, análise de dados e pesquisa científica.
Mais do que potência, o sistema oferece governança e confiabilidade — pilares indispensáveis em ambientes empresariais e acadêmicos de missão crítica. À medida que os modelos de IA e as simulações avançam, soluções como esta se tornam o núcleo das fábricas de inteligência corporativa e dos data centers científicos do futuro.


















