


Introdução: desempenho extremo como alicerce da inovação em IA e HPC
No atual cenário de inteligência artificial e computação de alto desempenho (HPC), a capacidade de processar volumes massivos de dados e treinar modelos complexos de deep learning é um diferencial competitivo decisivo. Organizações de pesquisa, instituições financeiras, laboratórios científicos e data centers corporativos exigem sistemas com densidade computacional e eficiência energética máximas.
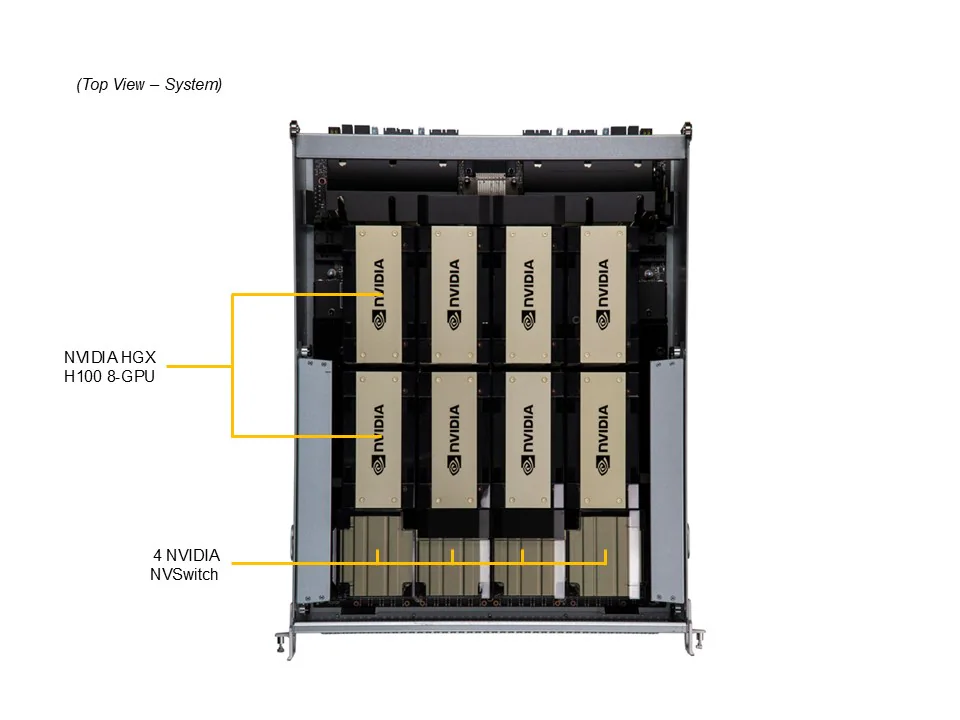
É neste contexto que a Supermicro apresenta o DP AMD 8U System with NVIDIA HGX H100/H200 8-GPU, um sistema certificado pela NVIDIA e projetado segundo os padrões OCP (Open Compute Project) para oferecer desempenho, confiabilidade e escalabilidade superiores.
O desafio empresarial vai além da simples potência bruta: trata-se de alinhar arquiteturas de hardware avançadas — como CPUs AMD EPYC™ 9004, GPUs NVIDIA HGX e interconexões NVLink™ — à governança, eficiência energética e gestão centralizada. O custo da inação, nesse contexto, é claro: gargalos de performance, desperdício energético e incapacidade de escalar projetos de IA de forma previsível e segura.
O desafio estratégico: escalar IA e HPC sem comprometer eficiência
Empresas que investem em IA e HPC enfrentam um dilema constante: como aumentar a capacidade computacional sem elevar exponencialmente os custos operacionais e o consumo energético. Modelos de linguagem de larga escala (LLMs), simulações científicas e workloads de análise preditiva demandam infraestrutura com altíssima largura de banda entre GPU e CPU, suporte a memórias DDR5 e conectividade PCIe 5.0.
Tradicionalmente, sistemas baseados em múltiplas GPUs sofrem com limitações de interconexão, atrasos de latência e gargalos no fluxo de dados. Em ambientes de HPC, isso representa perda direta de desempenho e aumento no tempo de execução das cargas.
A Supermicro aborda esse problema com uma solução arquitetural de alta densidade e interconexão otimizada, eliminando o tradicional compromisso entre potência e eficiência térmica. O servidor AMD 8U com NVIDIA HGX H100/H200 é, portanto, uma resposta direta às exigências de IA moderna e computação científica em escala.
Consequências da inação: quando a infraestrutura se torna o gargalo
A ausência de uma infraestrutura otimizada para GPU pode gerar efeitos sistêmicos: atrasos na entrega de modelos de IA, aumento de custo energético e incapacidade de atender a padrões de confiabilidade exigidos por setores regulados.
Workloads de treinamento distribuído em redes ineficientes causam desperdício de processamento — o que impacta diretamente o ROI de projetos de IA corporativa. Além disso, data centers que não adotam soluções de refrigeração e gerenciamento inteligente de energia enfrentam riscos de sobrecarga térmica e degradação prematura dos componentes.
Por outro lado, o DP AMD 8U oferece 10 ventoinhas de alta capacidade com controle otimizado de velocidade, garantindo estabilidade térmica e desempenho contínuo. A combinação de seis fontes redundantes Titanium Level de 3000W (3+3) assegura alta disponibilidade mesmo em cargas intensas, reduzindo falhas operacionais e ampliando o ciclo de vida da infraestrutura.
Fundamentos da solução: arquitetura de precisão para IA e HPC
A base técnica do Supermicro DP AMD 8U é composta por duas colunas de força:
Processadores AMD EPYC™ 9004 (até 128 núcleos/256 threads, 400W TDP)
Plataforma NVIDIA HGX™ H100/H200 8-GPU com NVSwitch™
Essa combinação cria uma topologia de comunicação extremamente eficiente, permitindo interconexão GPU-GPU via NVLink™ e GPU-CPU via PCIe 5.0 x16. O resultado é uma redução drástica da latência e um aumento significativo na largura de banda entre as unidades de processamento.
O sistema suporta até 6 TB de memória DDR5 ECC RDIMM 4800MT/s distribuída em 24 slots DIMM, garantindo consistência e velocidade em operações de inferência e treinamento. A ECC (Error Correction Code) mantém a integridade dos dados em tempo real, recurso crítico em ambientes de modelagem científica e automação industrial.

Implementação estratégica: flexibilidade, segurança e governança
A arquitetura de 8U foi projetada para integração em data centers de missão crítica. Com até 18 baias hot-swap, sendo 12 NVMe, 4 NVMe adicionais opcionais e 2 SATA, o sistema permite expansão modular e substituição sem downtime.
No campo da segurança, o servidor implementa uma raiz de confiança de hardware (Silicon Root of Trust) compatível com o padrão NIST 800-193, além de TPM 2.0, firmware assinado criptograficamente, Secure Boot, e atestado remoto de cadeia de suprimentos. Essa abordagem garante que o ambiente de IA esteja protegido desde o firmware até o runtime operacional.
A gestão centralizada é realizada via SuperCloud Composer®, Supermicro Server Manager (SSM) e SuperDoctor® 5 (SD5), que proporcionam visibilidade completa sobre saúde do sistema, consumo energético e controle térmico. Esses recursos simplificam a administração de clusters com múltiplos servidores GPU, otimizando custos operacionais.
Melhores práticas avançadas: desempenho e eficiência em equilíbrio
A operação eficiente do DP AMD 8U requer alinhamento entre hardware e políticas de orquestração de workloads. Em aplicações de treinamento distribuído, o uso do RDMA (Remote Direct Memory Access) — viabilizado por 8 NICs com conectividade direta GPU-a-GPU (1:1) — garante latência ultrabaixa entre nós de processamento.
Do ponto de vista de eficiência energética, as fontes Titanium Level (96%) e o gerenciamento dinâmico de ventiladores reduzem o consumo sem comprometer o throughput. Em termos de manutenção, o design modular e o suporte a PCIe 5.0 permitem futuras atualizações sem reengenharia do sistema.
Empresas que implementam políticas de automação via SuperServer Automation Assistant (SAA) ou Supermicro Update Manager (SUM) ampliam a resiliência operacional, garantindo que atualizações de firmware e diagnósticos offline sejam executados sem afetar a disponibilidade do ambiente.
Medição de sucesso: avaliando desempenho e confiabilidade
O sucesso na adoção do servidor AMD 8U com NVIDIA HGX H100/H200 pode ser mensurado por métricas como:
Aceleração de treinamento de modelos de IA (comparando throughput por watt)
Eficiência térmica e estabilidade operacional sob carga máxima
Tempo médio entre falhas (MTBF) em operações de 24×7
Escalabilidade linear em clusters multi-nó com interconexão NVSwitch
Essas métricas traduzem-se em ganhos tangíveis: redução de tempo de treinamento, melhor utilização de GPU e maior previsibilidade de custos. A arquitetura otimizada para PCIe 5.0 e NVLink permite que workloads de IA complexos sejam executados com mínima interferência entre dispositivos, garantindo escalabilidade consistente.
Conclusão: o novo paradigma de performance para IA corporativa
O Supermicro DP AMD 8U System with NVIDIA HGX H100/H200 8-GPU representa o ápice da engenharia para cargas de trabalho de IA, HPC e modelagem científica. Sua combinação de arquitetura AMD EPYC 9004, NVSwitch/NVLink, memória DDR5 ECC e segurança baseada em hardware o torna uma plataforma ideal para organizações que buscam performance extrema com governança e sustentabilidade.
Mais do que uma solução de hardware, trata-se de uma base estratégica para acelerar inovações em setores como finanças, saúde, pesquisa e manufatura inteligente. A convergência entre densidade computacional, eficiência térmica e segurança de firmware redefine o padrão de confiabilidade para data centers modernos.
Para organizações que visam liderança em IA e HPC, investir em uma infraestrutura de classe Supermicro Gold Series significa preparar-se para o futuro — onde a capacidade de processar, proteger e escalar será o diferencial competitivo definitivo.


















