


Servidor 4U AMD Dual-Root com 8 GPUs: Performance e Escalabilidade Empresarial
No cenário atual de tecnologia empresarial, a demanda por soluções de computação de alto desempenho (HPC) e inteligência artificial (AI) está crescendo de forma exponencial. Organizações que atuam em setores como deep learning, simulações científicas complexas, molecular dynamics e cloud gaming precisam de servidores capazes de fornecer processamento massivo paralelo, alta largura de banda entre CPU e GPU e escalabilidade sem comprometer a confiabilidade.
O Servidor 4U AMD Dual-Root com 8 GPUs da Supermicro surge como uma solução estratégica para empresas que enfrentam desafios críticos de desempenho e capacidade de processamento. Sua arquitetura com processadores AMD EPYC e suporte a GPUs duplas de alta performance permite lidar com cargas de trabalho intensivas, reduzindo o tempo de execução de projetos complexos e aumentando a competitividade organizacional.
Ignorar ou subdimensionar a infraestrutura para HPC e AI pode gerar atrasos em pesquisas, perda de oportunidades de inovação e aumento de custos operacionais. Este artigo explora detalhadamente os fundamentos técnicos, estratégias de implementação e melhores práticas para maximizar o retorno sobre investimento (ROI) neste tipo de solução.
Serão abordados: arquitetura do sistema, interconexão CPU-GPU, gerenciamento de memória, armazenamento, rede, segurança, resiliência e métricas de desempenho, permitindo uma visão completa para decisões estratégicas e técnicas.
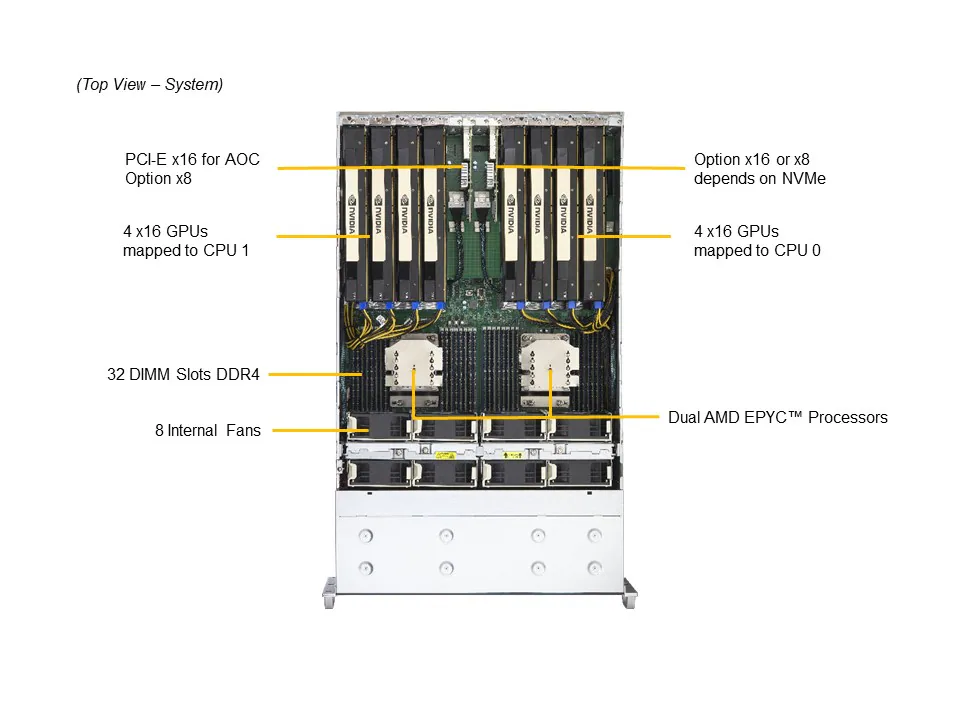
Desafios Estratégicos de Computação de Alto Desempenho
Complexidade de cargas de trabalho HPC e AI
Organizações que utilizam AI, deep learning e simulações científicas enfrentam desafios significativos relacionados à paralelização de tarefas, volume de dados e requisitos de latência. Processamentos tradicionais não conseguem acompanhar a complexidade de algoritmos de aprendizado profundo, modelagem molecular ou renderização gráfica em tempo real.
O uso de múltiplas GPUs de alta capacidade, como o suporte a até 8 GPUs duplas neste servidor, permite distribuir operações massivamente paralelas, reduzindo gargalos de processamento e acelerando resultados. A interconexão via NVLink com NVSwitch maximiza a largura de banda GPU-GPU, essencial para tarefas que exigem compartilhamento intensivo de dados entre aceleradores.
Riscos da infraestrutura inadequada
Subestimar as necessidades de computação pode resultar em: atrasos de projeto, custos de energia mais altos, falhas em deadlines estratégicos e limitação na experimentação de modelos de AI. Servidores mal configurados podem gerar gargalos de memória, saturação de I/O ou falhas em tarefas de processamento distribuído.
Fundamentos da Solução Supermicro AS-4124GS-TNR+
Arquitetura Dual-Root com AMD EPYC
O sistema utiliza processadores AMD EPYC™ 7002/7003 em configuração dual SP3, suportando CPUs com até 280W TDP. Esta arquitetura oferece alta contagem de núcleos e threads, crucial para paralelismo em cargas de trabalho HPC e AI, permitindo processar múltiplas tarefas simultaneamente com eficiência energética.
O design Dual-Root permite otimizar a comunicação interna e reduzir latência entre CPUs e GPUs, tornando o servidor altamente eficiente em operações complexas e de grande volume de dados.
GPU e interconexão de alta performance
O servidor suporta até 8 GPUs duplas ou simples, incluindo NVIDIA H100, A100, L40S, RTX 6000, entre outras, e AMD Instinct MI150. A interconexão via PCIe 4.0 x16 CPU-GPU e NVLink NVSwitch entre GPUs garante throughput máximo e baixa latência, essencial para deep learning, inferência de AI e simulações em escala.
Memória e armazenamento escaláveis
Com 32 slots DIMM, suporta até 8TB de ECC DDR4 3200MT/s, garantindo consistência e correção de erros em operações críticas. O armazenamento é flexível: até 24 baias hot-swap de 2.5″, combinando SATA e NVMe, e controladores RAID avançados permitem configuração de redundância e desempenho conforme a necessidade do projeto.

Implementação Estratégica e Gestão de Infraestrutura
Gerenciamento e software Supermicro
O SuperServer vem com ferramentas como SuperCloud Composer, Supermicro Server Manager, SuperDoctor 5 e SuperServer Automation Assistant, permitindo monitoramento detalhado, diagnóstico proativo e automação de tarefas repetitivas. Esses recursos reduzem risco operacional e facilitam escalabilidade futura.
Segurança e resiliência
O sistema inclui TPM 2.0, Silicon Root of Trust e firmware criptograficamente assinado, garantindo integridade de inicialização e proteção contra ataques de baixo nível. Além disso, fontes redundantes Titanium Level 96% e monitoramento de ventiladores e temperatura asseguram disponibilidade contínua em operações críticas.
Considerações de implementação
Para maximizar desempenho, recomenda-se balancear GPU e CPU de acordo com perfil de workload, configurar memória em dual DIMM por canal (2DPC) e otimizar armazenamento NVMe/SATA conforme prioridade de I/O. A integração com redes 1GbE e AOC customizadas permite flexibilidade de comunicação e escalabilidade em datacenters.
Melhores Práticas Avançadas
Otimização de workloads HPC e AI
Distribuir tarefas de treinamento AI entre GPUs com NVLink reduz overhead de sincronização. Aplicar técnicas de memory pooling e tuning de PCIe assegura que GPUs recebam dados na velocidade ideal, evitando subutilização do processamento paralelo.
Redundância e continuidade operacional
Configurar RAID 1 para drives críticos, empregar múltiplas fontes de alimentação redundantes e monitorar sensores de temperatura previne falhas inesperadas. Estratégias de failover podem ser implementadas via software de gerenciamento Supermicro, garantindo alta disponibilidade em datacenters corporativos.
Medição de Sucesso
Métricas de desempenho
Indicadores como throughput PCIe, largura de banda NVLink, utilização de GPU, tempo médio de resposta e IOPS de armazenamento são cruciais para avaliar eficiência do servidor. Monitoramento contínuo permite ajustes finos e planejamento de expansão.
Indicadores de ROI
Redução de tempo de treinamento AI, menor latência em simulações, maior densidade computacional por rack e eficiência energética medem o retorno sobre o investimento. Implementações bem planejadas garantem escalabilidade sem comprometer custo operacional.
Conclusão
O Servidor 4U AMD Dual-Root com 8 GPUs é uma solução robusta e estratégica para organizações que buscam performance extrema em HPC, deep learning e simulações avançadas. Sua arquitetura balanceada entre CPU e GPU, memória massiva e armazenamento flexível proporciona confiabilidade, escalabilidade e segurança.
Empresas que implementam esta infraestrutura ganham vantagem competitiva, capacidade de inovação acelerada e mitigam riscos operacionais associados a cargas de trabalho críticas. A integração com ferramentas de gerenciamento e monitoramento da Supermicro garante governança, compliance e continuidade operacional.
Perspectivas futuras incluem expansão para novas gerações de GPUs e CPUs, integração com AI federada e otimizações de NVLink para workloads cada vez mais massivos, mantendo a solução alinhada com tendências de HPC e AI corporativa.
Próximos passos incluem avaliação detalhada de workloads, planejamento de escalabilidade, configuração de armazenamento e rede, e treinamento das equipes técnicas para maximizar o potencial desta solução.


















