


Servidor 4U AMD com 8 GPUs NVIDIA HGX A100 para HPC e AI
Introdução
No cenário atual de computação de alto desempenho (HPC) e inteligência artificial (AI), a demanda por sistemas com capacidade massiva de processamento paralelo está crescendo de forma exponencial. Organizações de pesquisa, laboratórios de dados e provedores de serviços de nuvem enfrentam desafios significativos para processar grandes volumes de dados em tempo hábil, enquanto mantêm eficiência energética e confiabilidade operacional.
Um dos maiores desafios críticos é a comunicação eficiente entre GPUs em sistemas multi-GPU. Latência e largura de banda insuficientes podem se tornar gargalos severos em aplicações de deep learning e análise científica de grande escala. A implementação inadequada de sistemas HPC também pode gerar custos elevados de energia e manutenção, além de comprometer o desempenho e a escalabilidade.
Este artigo aborda o DP AMD System com NVIDIA HGX A100 8-GPU, detalhando arquitetura, recursos avançados, integração com AI/Deep Learning e melhores práticas de implementação em data centers. Analisaremos impactos estratégicos, trade-offs técnicos e métricas de sucesso para organizações que buscam maximizar a performance em HPC e AI.

Problema Estratégico
Empresas e centros de pesquisa enfrentam um dilema: como escalar cargas de trabalho de HPC e AI mantendo eficiência energética e consistência de desempenho entre GPUs. Sistemas tradicionais multi-GPU frequentemente sofrem com limitações de interconexão, tornando o processamento distribuído ineficiente.
Além disso, a integração com infraestrutura existente, gerenciamento térmico e redundância de energia representam riscos críticos. Falhas nestes pontos podem comprometer a continuidade operacional e gerar perdas financeiras significativas.
Comunicação entre GPUs
A largura de banda de interconexão entre GPUs é um fator determinante. Sem tecnologia adequada, como NVLink v3 e NVSwitch, o sistema sofre gargalos em workloads que exigem alta transferência de dados entre GPUs, impactando treinamento de modelos de AI complexos.
Gerenciamento de Recursos
O gerenciamento de memória e CPU é outro ponto crítico. CPUs AMD EPYC dual, suportando até 280W TDP, combinadas com 32 DIMMs DDR4 ECC 3200MHz, proporcionam desempenho robusto, mas exigem monitoramento contínuo para evitar throttling e maximizar eficiência em workloads paralelos.
Consequências da Inação
Ignorar a escolha de arquitetura apropriada para HPC e AI pode resultar em tempos de processamento mais longos, desperdício de energia e limitação na escalabilidade. Organizações podem enfrentar atrasos críticos em pesquisas, análises preditivas e treinamento de modelos de IA de larga escala.
Falhas em redundância e gerenciamento térmico podem gerar downtime significativo, comprometendo SLAs e aumentando custos operacionais. Além disso, sistemas com baixa interoperabilidade podem exigir reconfigurações constantes, impactando produtividade e retorno sobre investimento.
Fundamentos da Solução
Arquitetura de GPU e Interconexão
O DP AMD System integra 8 GPUs NVIDIA HGX A100 com 40GB HBM2 ou 80GB HBM2e, interconectadas via NVLink v3 e NVSwitch. Este design oferece comunicação de alta largura de banda, essencial para treinamento de modelos de AI e workloads HPC que dependem de transferência massiva de dados.
O suporte a GPUDirect RDMA permite comunicação direta entre GPUs e NICs, reduzindo latência e overhead de CPU, essencial em ambientes de AI/Deep Learning distribuído.
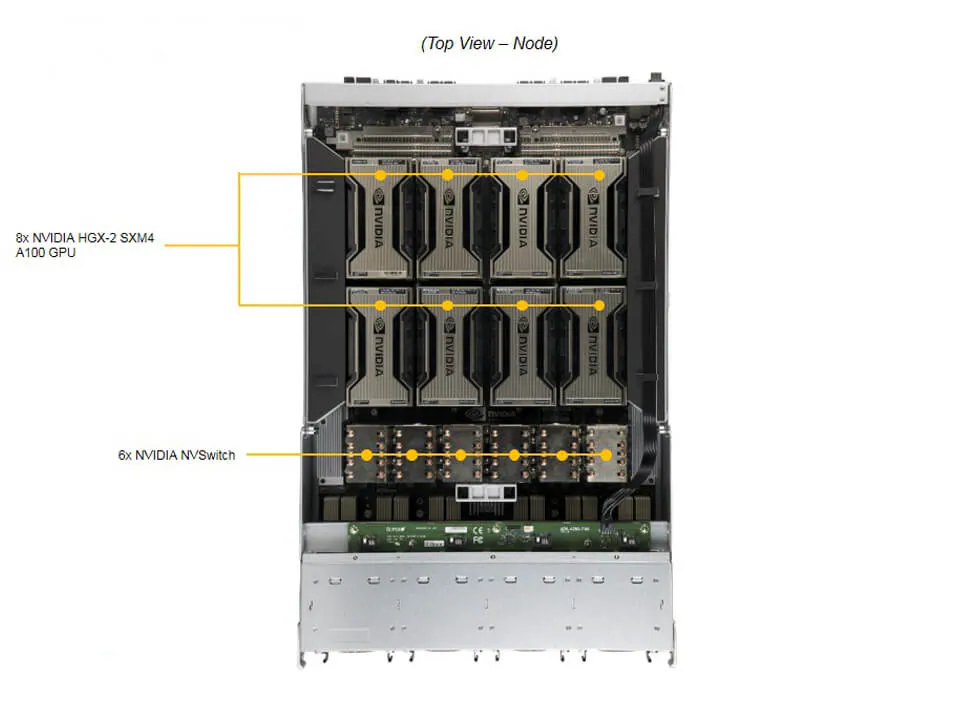
Processamento e Memória
Dual AMD EPYC 7002/7003 com 32 DIMMs DDR4 3200MHz ECC registradas oferecem capacidade de memória de 8TB, garantindo consistência e integridade em cálculos de alta precisão. A tecnologia AMD 3D V-Cache™ em modelos EPYC 7003 aumenta desempenho em workloads dependentes de cache, mas requer BIOS 2.3 ou superior.
Gerenciamento e Segurança
O sistema oferece Supermicro Server Manager (SSM), Power Manager (SPM) e SuperDoctor 5, possibilitando monitoramento em tempo real de CPUs, memória, ventiladores e temperatura do chassis. Recursos de segurança incluem TPM 2.0, Silicon Root of Trust, Secure Boot e firmware assinado, mitigando riscos de ataques a nível de hardware.
Implementação Estratégica
Integração com Data Center
Com formato 4U e 4x 2200W redundantes (3+1), o sistema é adequado para racks de alta densidade, mantendo eficiência energética e redundância de energia. Monitoramento de temperatura e controle de ventiladores PWM garantem operação estável em ambientes críticos.
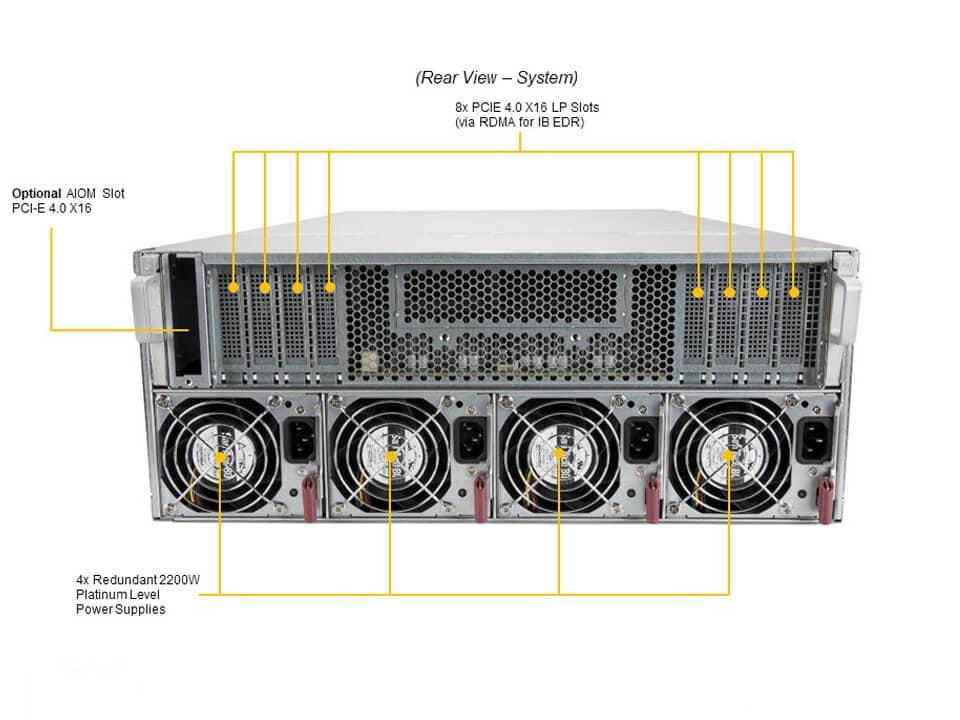
Configuração de Storage
O DP AMD System suporta até 10 bays NVMe 2.5″, combinando frontais hot-swap e traseiros, permitindo escalabilidade de armazenamento de alta velocidade. NVMe adicional requer controladora ou cabos específicos, destacando a importância de planejamento de infraestrutura.
Melhores Práticas Avançadas
Otimização de Workloads AI
Para workloads de AI distribuído, é recomendada a configuração 1:1 de NIC para GPU via GPUDirect RDMA, minimizando latência e maximizando throughput. Balanceamento de carga entre CPUs e GPUs é essencial para evitar estrangulamento de pipelines de dados.
Monitoramento Proativo
Utilizar SSM, SPM e SD5 para análise contínua de performance permite ajustes de ventilação, clock e consumo energético. A aplicação de políticas de firmware seguro garante mitigação de vulnerabilidades e continuidade operacional.
Medição de Sucesso
O sucesso da implementação pode ser medido através de métricas como throughput em treinamento de AI, latência de comunicação entre GPUs, eficiência energética (PUE), tempo de disponibilidade (uptime) e integridade de dados em memória ECC. Benchmarks de workloads reais oferecem indicadores confiáveis para avaliação de performance e ROI.
Conclusão
O DP AMD System com NVIDIA HGX A100 8-GPU é uma solução robusta para HPC e AI, combinando alto desempenho de processamento, interconexão eficiente e recursos avançados de segurança. Sua arquitetura 4U dual AMD EPYC com 32 DIMMs DDR4 e suporte a NVLink v3 + NVSwitch garante comunicação rápida entre GPUs, essencial para workloads críticos.
A adoção estratégica deste sistema reduz riscos de downtime, otimiza performance em AI/Deep Learning e oferece escalabilidade de memória e armazenamento NVMe. A implementação cuidadosa e monitoramento proativo asseguram alinhamento com objetivos de negócio e eficiência operacional.
Perspectivas futuras incluem expansão de capacidade de GPU e armazenamento, integração com novas tecnologias NVIDIA e aprimoramentos em gerenciamento inteligente de data centers. Organizações que buscam liderança em HPC e AI devem considerar esta plataforma como base para crescimento sustentável e competitivo.


















