






Descrição
Visão Geral do Produto
O 1U 2-Node NVIDIA GH200 Grace Hopper Superchip System é um servidor de alta densidade projetado para aplicações de High Performance Computing (HPC), Deep Learning e Large Language Models (LLM). Cada node integra a inovadora tecnologia NVIDIA Grace Hopper Superchip, combinando CPU Grace de até 72 cores e GPU H100 Tensor Core, oferecendo desempenho extremo em um formato compacto 1U. Seu design suporta liquid cooling para CPUs de alto TDP e até 8 drives E1.S NVMe, garantindo eficiência e confiabilidade para cargas críticas.
Características Técnicas
Hardware por Node
CPU: NVIDIA Grace CPU de 72 cores (GH200)
GPU: H100 Tensor Core (onboard)
GPU-GPU Interconnect: PCIe
Memória
Onboard: Até 480GB ECC LPDDR5X
GPU Memory: Até 96GB ECC HBM3
Armazenamento
Drive Bays: 4 frontais hot-swap E1.S NVMe
M.2 Slots: 2 M.2 NVMe (M-key)
Conectividade
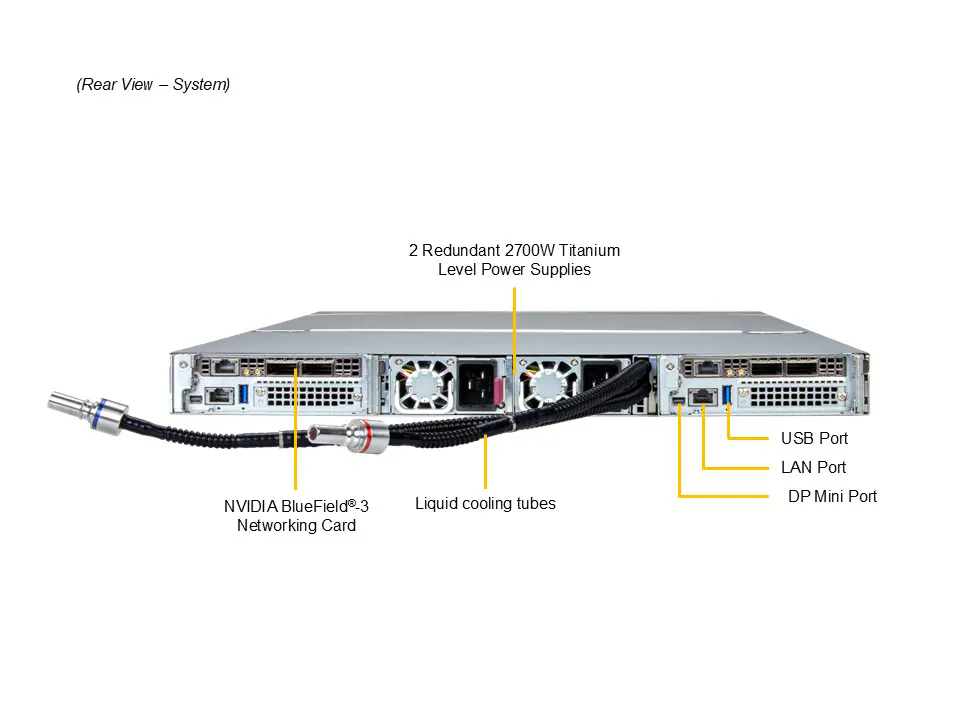
LAN: 1 RJ45 1GbE BMC
USB: 1 porta (rear)
Vídeo: 1 mini-DP
Expansão
1 PCIe 5.0 x16 FHFL
1 PCIe 5.0 x16 LP
Sistema e BIOS
Chipset: SoC
BIOS: AMI 64MB SPI Flash EEPROM
Gerenciamento: Monitoração de CPU, memória, ventoinhas, temperatura e ACPI power
Energia e Ambiente
Fonte: 2x 2700W redundantes, nível Titanium (96%)
Temperatura de Operação: 10°C – 35°C
Umidade Relativa: 8% – 90% (não condensante)
Características Físicas
Formato: 1U Rackmount
Dimensões: 43.6 mm H x 438.4 mm W x 900 mm D
Peso Líquido: 15.26 kg
Cooling
Até 7 ventoinhas removíveis de 4cm
Suporte a liquid cooling D2C (Direct-to-Chip)
Benefícios e Aplicações
Desempenho extremo: CPU Grace 72 cores + GPU H100 para IA, HPC e LLMs
Alta densidade: 2 nodes em 1U, ideal para data centers compactos
Armazenamento rápido: Suporte a E1.S NVMe e M.2 NVMe para alta IOPS
Eficiência térmica: Suporte liquid cooling e monitoramento inteligente de ventoinhas
Flexibilidade de expansão: Slots PCIe 5.0 para GPUs adicionais ou aceleradores
Especificações Técnicas Organizadas por Grupo
CPU & GPU
CPU: NVIDIA Grace 72 cores GH200 (TDP até 2000W, liquid cooled)
GPU: H100 Tensor Core
GPU Memory: 96GB ECC HBM3
Memória
LPDDR5X ECC até 480GB onboard
Armazenamento
4x E1.S NVMe hot-swap
2x M.2 NVMe
Conectividade & I/O
LAN: 1GbE BMC
USB: 1 porta
Vídeo: mini-DP
PCIe: 1×16 FHFL + 1×16 LP
Energia & Ambiente
2x 2700W Titanium PSU
Temp.: 10°C – 35°C
Umidade: 8% – 90%
Dimensões & Peso
Altura: 43.6 mm
Largura: 438.4 mm
Profundidade: 900 mm
Peso líquido: 15.26 kg
Cooling
Até 7 ventoinhas 4cm
D2C Liquid Cooling opcional
Conclusão
O 1U 2-Node NVIDIA GH200 Grace Hopper Superchip System combina alta performance, densidade compacta e eficiência energética, sendo ideal para HPC, IA, deep learning e LLMs. Sua integração de CPU Grace + GPU H100 e suporte a liquid cooling garante confiabilidade, escalabilidade e desempenho incomparável. Este servidor representa a solução ideal para data centers que exigem potência máxima em 1U.
FAQ – Perguntas Frequentes (SEO e GEO Otimizado)
1. Qual a principal aplicação do servidor 1U 2-Node NVIDIA GH200?
O servidor é ideal para High Performance Computing (HPC), treinamento de IA, Deep Learning e execução de Large Language Models (LLMs) em data centers de alta densidade.
2. Quantas GPUs o sistema suporta por node?
Cada node suporta 1 GPU H100 Tensor Core onboard e possui interconexão PCIe para expansões adicionais.
3. O servidor suporta resfriamento líquido?
Sim, o sistema oferece liquid cooling D2C opcional para CPUs de alto TDP e gerenciamento eficiente de temperatura.
4. Qual é a capacidade máxima de memória do sistema?
Até 480GB de LPDDR5X ECC por node, com 96GB ECC HBM3 para GPU.
5. Quais tipos de armazenamento são compatíveis?
Suporte para 4 hot-swap E1.S NVMe drive bays e 2 slots M.2 NVMe, garantindo alta performance e IOPS.
6. Qual é o consumo de energia do servidor?
O sistema utiliza 2 fontes redundantes de 2700W, nível Titanium (96%), garantindo eficiência energética e confiabilidade.
7. Qual o tamanho do servidor?
Formato 1U Rackmount, dimensões de 43.6 mm H x 438.4 mm W x 900 mm D.
8. O servidor é adequado para racks de alta densidade?
Sim, o design 1U 2-Node permite alta densidade em data centers compactos, mantendo performance máxima.
9. Como é o gerenciamento do servidor?
Inclui monitoramento de CPU, memória, ventoinhas e temperatura, além de suporte a ACPI power management.
10. Quais aplicações de IA podem ser executadas?
Treinamento de modelos de Deep Learning, LLMs, IA generativa, análise científica, simulações complexas e HPC.






















