Review supermicro GPU ARS-111GL-DNHR-LCC

1U 2-Node NVIDIA GH200: Desempenho Máximo em HPC e IA Empresarial
O avanço das demandas de High Performance Computing (HPC) e Inteligência Artificial (IA) exige soluções de hardware que combinem densidade, escalabilidade e eficiência energética. O sistema 1U 2-Node NVIDIA GH200 Grace Hopper Superchip surge como resposta a essa necessidade, oferecendo desempenho extremo em um espaço físico compacto, ideal para data centers corporativos que buscam maximizar capacidade computacional sem comprometer espaço ou eficiência.

Introdução
Contextualização Estratégica
Empresas líderes em setores de pesquisa científica, finanças e modelagem preditiva estão cada vez mais dependentes de sistemas capazes de processar grandes volumes de dados em paralelo. A integração do NVIDIA GH200 Grace Hopper Superchip em um formato 1U de alta densidade permite que organizações aumentem significativamente a capacidade de processamento, mantendo operações de data center enxutas e controlando custos de energia e refrigeração.
Desafios Críticos
Os desafios técnicos incluem gerenciamento térmico, latência de comunicação entre CPU e GPU e integração com infraestrutura existente. Sem uma arquitetura otimizada, a performance de cargas de trabalho críticas de IA e LLM pode ser seriamente limitada, impactando prazos de entrega e eficiência operacional.
Custos e Riscos da Inação
A não atualização de sistemas para plataformas modernas como a 1U 2-Node NVIDIA GH200 pode resultar em custos elevados de oportunidade, maior consumo de energia, menor throughput em análise de dados e perda de competitividade frente a empresas que adotam soluções HPC avançadas.
Visão Geral do Artigo
Este artigo detalhará o desafio estratégico de alta densidade computacional, explorará as consequências da inação, apresentará os fundamentos técnicos do GH200, abordará a implementação estratégica e práticas avançadas, e finaliza com métricas de sucesso para avaliar a eficácia da solução.
Desenvolvimento
Problema Estratégico
Organizações que dependem de processamento intensivo de IA enfrentam gargalos significativos em infraestrutura tradicional. A comunicação entre CPU e GPU é um fator crítico: latências elevadas podem degradar o desempenho em tarefas de treinamento de LLM ou inferência em deep learning. Soluções convencionais de 2U ou 4U podem ocupar mais espaço, aumentar consumo de energia e complicar a manutenção física do data center.
Consequências da Inação
Manter sistemas legados implica menor densidade de computação, maior consumo energético por operação e aumento do risco de falhas térmicas. Além disso, a incapacidade de processar workloads de IA em tempo real pode resultar em atrasos na entrega de insights estratégicos, afetando diretamente decisões de negócio e inovação.
Fundamentos da Solução
O 1U 2-Node NVIDIA GH200 combina dois nós em um único rack 1U, cada um equipado com:
- CPU NVIDIA Grace de 72 núcleos, integrando processamento de IA e gerenciamento de memória eficiente.
- GPU NVIDIA H100 Tensor Core, on-board, com interconexão NVLink Chip-2-Chip (C2C) de alta largura de banda (900GB/s) para comunicação ultra-rápida entre CPU e GPU.
- Memória onboard LPDDR5X de até 480GB ECC, mais até 96GB ECC HBM3 dedicada à GPU.
- Armazenamento direto E1.S NVMe, além de slots M.2 NVMe, permitindo I/O de altíssima performance.
Essa arquitetura permite throughput elevado, baixa latência e maior eficiência energética, crucial para workloads de treinamento de deep learning e inferência em LLMs.
Implementação Estratégica
A implantação exige avaliação do layout físico do data center, garantindo fluxo de ar adequado e refrigeração eficiente, especialmente quando a opção de resfriamento direto ao chip (D2C) é utilizada. O gerenciamento de energia, com fontes redundantes Titanium 2700W, assegura continuidade operacional mesmo em cenários críticos.
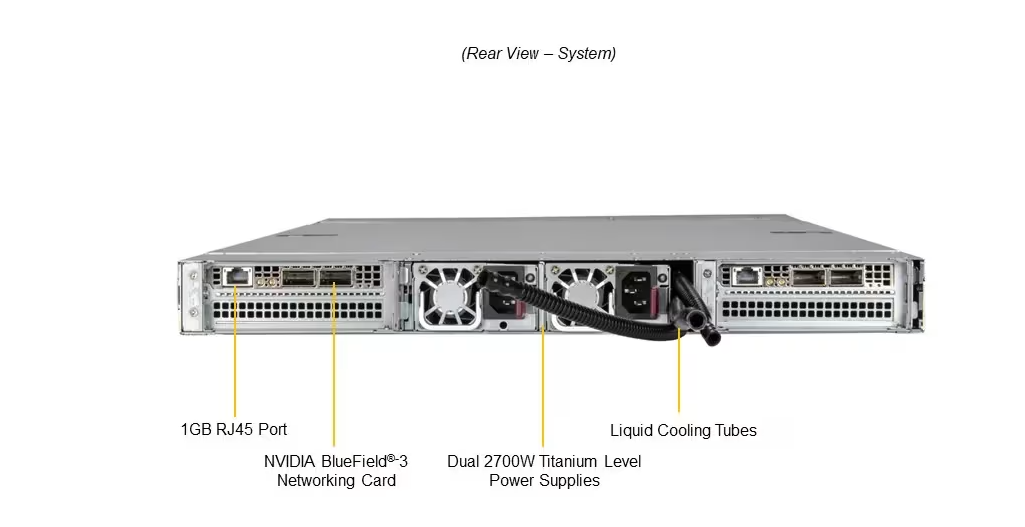
Integração com sistemas de rede existentes deve considerar compatibilidade com NVIDIA BlueField-3 ou ConnectX-7 para maximizar desempenho de interconexão e permitir virtualização de recursos de GPU quando necessário.
Melhores Práticas Avançadas
Para workloads distribuídos, recomenda-se balancear tarefas entre os dois nós para otimizar utilização da memória ECC e throughput NVLink. A monitoração constante via BIOS AMI e ferramentas de gerenciamento permite ajustes dinâmicos em ventoinhas, temperatura e consumo, prevenindo degradação de performance ou falhas térmicas.
Além disso, o planejamento de expansão deve considerar slots PCIe 5.0 x16 FHFL e M.2 adicionais, garantindo escalabilidade sem comprometer densidade 1U.
Medição de Sucesso
Métricas críticas incluem:
- Throughput em operações de treinamento de IA (TFLOPS ou operações por segundo).
- Latência entre CPU e GPU via NVLink C2C.
- Eficiência energética medida em desempenho por watt.
- Taxa de utilização de memória ECC e HBM3.
- Disponibilidade e uptime do sistema com monitoramento contínuo de temperaturas e voltagens.
Esses indicadores fornecem visão clara da performance operacional e retorno sobre investimento em ambientes empresariais de alta demanda.
Conclusão
Resumo dos Pontos Principais
O 1U 2-Node NVIDIA GH200 oferece solução compacta, eficiente e de altíssimo desempenho para HPC, IA e LLM, integrando Grace CPU, H100 GPU, NVLink C2C e memória ECC avançada. Sua arquitetura aborda gargalos críticos de latência, densidade e escalabilidade.
Considerações Finais
Investir em plataformas de alta densidade como o GH200 é estratégico para organizações que buscam maximizar capacidade computacional, reduzir custos de energia e acelerar inovação em IA e deep learning.
Perspectivas Futuras
A evolução de arquiteturas 1U com integração CPU-GPU tende a se expandir, com maior densidade de memória, interconexões de mais alta largura de banda e suporte a workloads ainda mais complexos de IA e LLM.
Próximos Passos Práticos
Empresas devem avaliar suas demandas de processamento, planejar a infraestrutura de refrigeração e energia, e preparar a integração de rede e armazenamento para adotar sistemas 1U 2-Node GH200 de forma eficiente e segura.

