Review supermicro GPU ARS-221GL-NHIR

Introdução
Em um cenário empresarial cada vez mais orientado por inteligência artificial, aprendizado de máquina e grandes modelos de linguagem (LLMs), a necessidade de infraestrutura de computação de alto desempenho é crítica. Organizações enfrentam desafios de escalabilidade, latência e complexidade de integração que impactam diretamente a velocidade de inovação e a competitividade no mercado.
A adoção inadequada ou a ausência de sistemas especializados para cargas de trabalho intensivas de IA e HPC pode resultar em custos operacionais elevados, desperdício de recursos e atrasos significativos em projetos estratégicos. Além disso, problemas de interoperabilidade entre CPU e GPU ou limitações de memória podem comprometer modelos avançados de inferência e treinamento.
Este artigo oferece uma análise detalhada do Supermicro 2U GPU GH200 Grace Hopper Superchip System, destacando arquitetura, desempenho, interconectividade e implicações estratégicas para organizações que buscam excelência em inteligência artificial, HPC e LLMs.

Problema Estratégico
Empresas que executam projetos de inteligência artificial e HPC enfrentam um dilema crítico: como conciliar densidade computacional, eficiência energética e latência mínima em um único sistema. A complexidade aumenta com modelos generativos que demandam largura de banda de memória extremamente alta e coerência entre CPU e GPU.
Soluções tradicionais de múltiplos servidores ou GPU separadas não conseguem oferecer a interconectividade necessária para LLMs de próxima geração. A limitação de memória e a baixa taxa de transferência entre CPU e GPU tornam o treinamento e a inferência mais lentos, elevando custos e reduzindo competitividade.
Consequências da Inação
Ignorar a necessidade de um sistema integrado como o GH200 implica riscos significativos: atrasos no desenvolvimento de produtos de IA, consumo excessivo de energia e maior complexidade operacional. Além disso, a falta de recursos avançados de interconexão e memória coerente pode limitar a escalabilidade de modelos generativos, impactando diretamente a capacidade de inovação da organização.
Fundamentos da Solução
O Supermicro 2U GPU GH200 oferece uma arquitetura unificada que combina dois GPUs NVIDIA H100 com dois CPUs Arm Neoverse V2 de 72 núcleos em cada GH200 Grace Hopper Superchip. A integração do NVLink Chip-to-Chip (C2C) permite comunicação de alta largura de banda (900GB/s) entre CPU e GPU, crucial para cargas de trabalho intensivas de IA e HPC.
O sistema suporta até 1248GB de memória coerente, distribuídos entre 960GB de LPDDR5X e 288GB de HBM3e nos GPUs, oferecendo recursos para manipulação de grandes modelos de linguagem sem gargalos. Essa configuração garante que operações de treinamento e inferência ocorram com máxima eficiência e mínima latência.
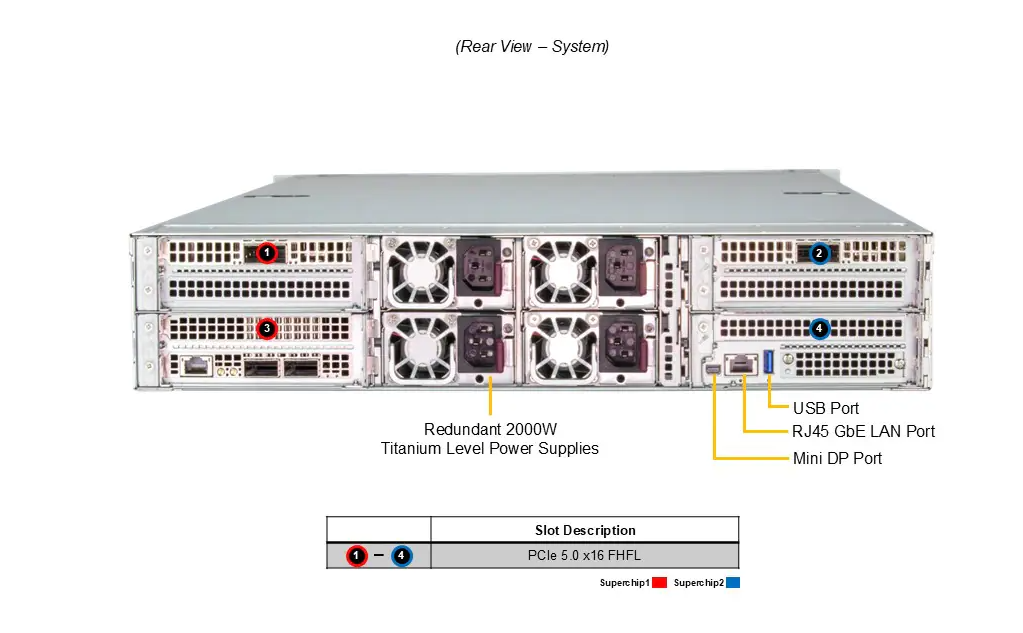
O design inclui 4 slots PCIe 5.0 x16, permitindo integração de NVIDIA BlueField-3 e ConnectX-7 para aceleração de rede e armazenamento remoto, ampliando ainda mais a capacidade de processamento distribuído e de edge AI.
Implementação Estratégica
A implementação exige consideração detalhada de resfriamento, energia e integração com software de gerenciamento de data center. O sistema vem equipado com até 6 ventiladores de alta performance com controle opcional de velocidade, garantindo estabilidade térmica mesmo sob cargas máximas.
Quatro fontes redundantes de 2000W em nível Titanium proporcionam resiliência energética, minimizando riscos de downtime em operações críticas. A compatibilidade com sistemas de monitoramento de CPU, memória e ventoinhas via BMC permite gestão proativa e alinhamento com políticas de governança e compliance.
Melhores Práticas Avançadas
Para maximizar desempenho, recomenda-se alocar modelos LLM em memória HBM3e sempre que possível, enquanto a LPDDR5X gerencia tarefas auxiliares. A utilização de NVLink para comunicação CPU-GPU e GPU-GPU reduz latência, permitindo treinamento de modelos generativos em escala de produção.
Integração com aceleradores de rede BlueField-3 permite offload de tarefas de I/O e segurança, liberando ciclos de GPU para processamento direto de IA. Estratégias de balanceamento de carga e gestão de energia devem ser implementadas para otimizar operação contínua e evitar throttling térmico.
Medição de Sucesso
Indicadores chave incluem throughput de treinamento de modelos LLM (tokens por segundo), latência de inferência, utilização de memória coerente e eficiência energética. Monitoramento contínuo do NVLink, ventoinhas e consumo de energia garante que o sistema opere dentro dos parâmetros ideais e fornece dados para ajustes de escalabilidade.
Conclusão
O Supermicro 2U GPU GH200 Grace Hopper Superchip System representa uma solução de ponta para organizações que buscam desempenho extremo em IA, LLMs e HPC. Sua arquitetura unificada, memória coerente e interconectividade NVLink oferecem vantagens significativas sobre soluções tradicionais de múltiplos servidores.
A adoção estratégica desse sistema reduz riscos operacionais, melhora a eficiência energética e maximiza a velocidade de desenvolvimento de aplicações de inteligência artificial. Organizações podem expandir suas capacidades de processamento de forma segura e escalável, mantendo competitividade em mercados de rápida evolução.
Perspectivas futuras incluem integração com tecnologias emergentes de interconexão e gerenciamento automatizado de workloads de IA, garantindo evolução contínua da infraestrutura de HPC e AI empresarial.
Próximos passos práticos envolvem planejamento de data center, configuração de resfriamento e energia, integração com software de gerenciamento e treinamento de equipes para operação otimizada, garantindo que a implementação do GH200 traga resultados estratégicos mensuráveis.

