Review supermicro GPU SuperServer SYS-221GE-TNHT-LCC

Servidor 2U GPU Intel Supermicro: Desempenho Máximo com NVIDIA HGX H100/H200
O SuperServer SYS-221GE-TNHT-LCC da Supermicro representa uma convergência de alta performance, densidade e escalabilidade em um sistema 2U otimizado para cargas de trabalho críticas de Inteligência Artificial (IA), aprendizado profundo, HPC e análise de dados avançada. Projetado para suportar até quatro GPUs NVIDIA HGX H100 ou H200, este servidor traz soluções de liquid cooling Direct-To-Chip (D2C) e uma arquitetura de memória robusta, permitindo às organizações enfrentar desafios técnicos complexos enquanto atendem às demandas de negócios estratégicos.
Introdução: Cenário Empresarial e Desafios de Implementação
Contextualização Estratégica
Em ambientes corporativos modernos, a necessidade por processamento paralelo de alta densidade é crítica. Aplicações de IA, modelagem climática, descoberta de fármacos e análise financeira exigem servidores capazes de fornecer throughput extremo sem comprometer estabilidade. A escolha de uma infraestrutura inadequada pode levar a gargalos computacionais e impactos diretos em tempo de desenvolvimento e competitividade.
Desafios Críticos
Organizações que buscam implementar servidores de alto desempenho enfrentam múltiplos desafios: otimização da comunicação entre CPUs e GPUs, gerenciamento térmico eficiente, maximização da largura de banda de memória e manutenção da confiabilidade em workloads intensivos. A integração entre hardware, software de gerenciamento e protocolos de rede exige análise estratégica para evitar falhas ou subutilização de recursos.
Custos e Riscos da Inação
Ignorar a necessidade de servidores 2U de alta densidade pode resultar em atrasos no processamento de dados críticos, aumento de custos operacionais devido à necessidade de mais servidores para cargas equivalentes e risco elevado de downtime. Além disso, soluções subótimas comprometem a eficiência energética e a escalabilidade futura, limitando a competitividade das empresas em setores orientados por dados.
Visão Geral do Conteúdo
Este artigo abordará detalhadamente a arquitetura do SuperServer SYS-221GE-TNHT-LCC, explorando fundamentos técnicos, implementação estratégica, otimizações avançadas e métricas de sucesso para avaliar eficácia. Cada seção conecta decisões técnicas a impactos de negócios, com foco em cenários críticos, trade-offs e interoperabilidade.
Problema Estratégico: Desafios em Servidores de Alta Performance
Complexidade de Integração CPU-GPU
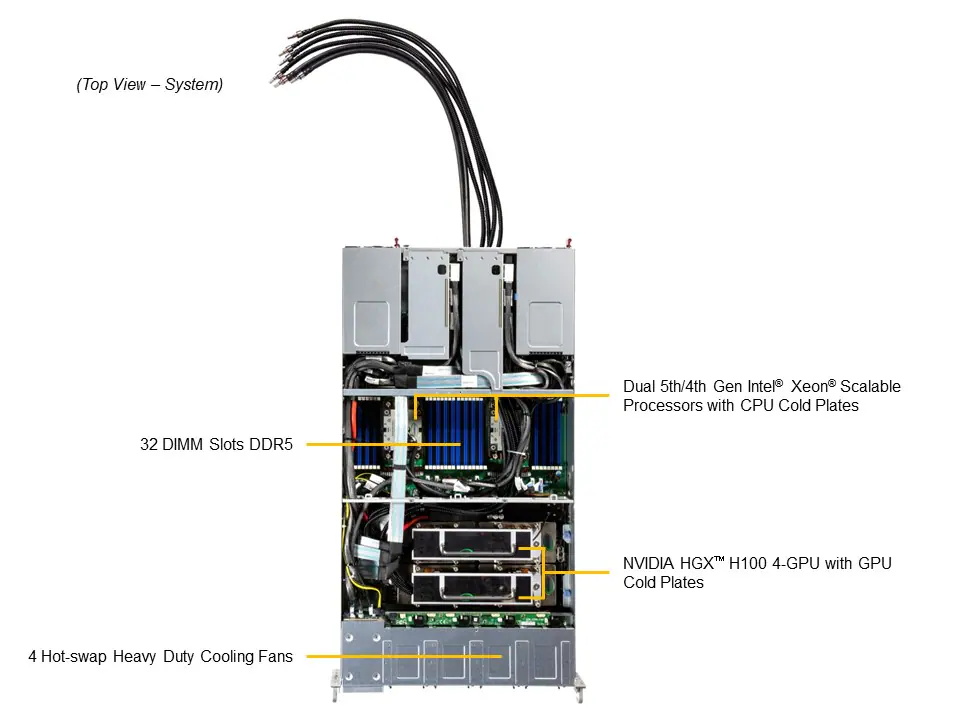
O SYS-221GE-TNHT-LCC suporta CPUs Intel Xeon 5ª e 4ª geração, com até 56 núcleos e 112 threads por processador, integrando-se com até quatro GPUs NVIDIA HGX via NVLink. Esse nível de integração garante comunicação de alta velocidade, mas requer planejamento preciso para balancear cargas de trabalho e evitar contenção de memória ou gargalos PCIe. A escolha do tipo de memória DDR5 ECC e sua distribuição em 32 DIMM slots impacta diretamente a eficiência de workloads intensivos em dados.
Desafios de Resfriamento e Eficiência Térmica
Servidores com GPUs de alto desempenho geram calor significativo. A solução Direct-To-Chip Liquid Cooling do Supermicro permite manter temperaturas operacionais ideais, porém exige infraestrutura especializada e monitoramento contínuo. O controle de quatro ventoinhas e o gerenciamento de fluxo de ar crítico asseguram que CPUs e GPUs operem dentro de parâmetros seguros, minimizando risco de throttling térmico e aumentando vida útil do equipamento.
Consequências da Inação
Impacto em Desempenho e Competitividade
Não investir em servidores otimizados para IA e HPC pode levar a atrasos em treinamentos de modelos de deep learning, análise de dados em tempo real e simulações científicas. A falta de comunicação eficiente entre CPU e GPU aumenta latência e reduz throughput, limitando a capacidade de responder rapidamente a demandas de mercado.
Riscos Operacionais
Infraestrutura inadequada expõe a empresa a falhas de hardware, downtime e maior consumo energético por unidade de processamento. Sem monitoramento integrado e redundância (como fontes de 5250W em configuração 1+1), organizações enfrentam risco elevado de interrupção crítica, o que pode comprometer contratos e reputação.

Fundamentos da Solução: Arquitetura e Capacidades Técnicas
Arquitetura de Processamento e Memória
O servidor é projetado para suportar até dois processadores Intel Xeon Scalable de 5ª/4ª geração, com capacidade de até 8TB de memória DDR5 5600 MT/s, distribuída em 32 DIMM slots. A alta densidade de memória e canais múltiplos garantem throughput elevado para aplicações HPC e IA. A compatibilidade com memória RDIMM/LRDIMM 3DS ECC oferece confiabilidade crítica para workloads intensivos.
GPU e Interconexão
Suporte a até quatro GPUs NVIDIA HGX H100 ou H200 conectadas via NVLink permite comunicação GPU-GPU de alta largura de banda, essencial para treinamento de modelos complexos de IA. A interconexão PCIe 5.0 x16 entre CPU e GPU assegura mínima latência, mantendo o pipeline de dados consistente e eficiente.
Armazenamento e Expansão
O chassi 2U inclui quatro baias hot-swap 2.5″ NVMe/SATA, além de dois slots M.2 NVMe dedicados ao boot. Essa configuração oferece alta performance de I/O e flexibilidade para expansão futura. A presença de quatro slots PCIe Gen 5.0 adicionais possibilita integração com aceleradores específicos ou controladoras de rede de alta velocidade, garantindo interoperabilidade com infraestruturas existentes.

Segurança e Gestão
Com Trusted Platform Module 2.0, Root of Trust, Secure Boot e criptografia de firmware, o SYS-221GE-TNHT-LCC assegura integridade de software e proteção contra ameaças à cadeia de suprimentos. Ferramentas de gerenciamento como SuperCloud Composer, SSM, SUM e SuperDoctor 5 permitem monitoramento, automação e diagnóstico avançado, integrando operações de TI com políticas de governança corporativa.
Implementação Estratégica
Planejamento de Workloads e Balanceamento
A definição de workloads adequados é crítica para aproveitar totalmente GPUs e CPUs. Distribuir tarefas de deep learning, simulações e análise de dados entre os quatro aceleradores HGX permite maximizar utilização, minimizar ociosidade e otimizar performance. Estratégias de agendamento e paralelização devem considerar latência PCIe e requisitos de memória.
Infraestrutura de Resfriamento e Energia
Implementar liquid cooling Direct-To-Chip exige análise de espaço físico, integração com sistemas de refrigeração existentes e monitoramento contínuo. Fontes redundantes de 5250W fornecem confiabilidade em ambientes críticos, garantindo que falhas de energia não interrompam operações.
Melhores Práticas Avançadas
Otimização de Comunicação GPU-GPU
NVLink permite comunicação de alta largura de banda, mas deve ser configurada com atenção a topologia física e filas de transmissão de dados. Ajustes finos na prioridade de tráfego e balanceamento de memória local versus compartilhada aumentam eficiência em treinamento de IA distribuído.
Gerenciamento de Memória e Latência
Para workloads que exigem até 8TB de memória, é fundamental configurar DIMMs corretamente em 1DPC ou 2DPC, considerando trade-offs entre velocidade e densidade. Estratégias de alocação de memória e cache de dados minimizam latência e aumentam consistência de performance.
Segurança e Compliance Contínuos
Monitoramento de integridade de firmware, atualizações seguras e configuração de políticas de lockdown do sistema garantem conformidade com padrões corporativos e regulatórios. Auditorias periódicas são recomendadas para garantir que protocolos de segurança permaneçam eficazes.
Medição de Sucesso
KPIs de Desempenho
Indicadores como throughput de GPU, latência de I/O, tempo de treinamento de modelos de IA, consumo energético por workload e uptime do sistema são métricas essenciais para avaliar a eficácia do investimento. Benchmarks específicos do setor devem ser utilizados para comparações consistentes.
Métricas de Operação e Gestão
Monitoramento contínuo via SSM e SuperCloud Composer permite rastrear temperatura, uso de memória, integridade de CPUs e GPUs, consumo de energia e alertas de falha. Essas métricas são críticas para manutenção proativa e escalabilidade futura.
Conclusão
Resumo dos Pontos Principais
O SuperServer SYS-221GE-TNHT-LCC combina densidade 2U, até quatro GPUs NVIDIA HGX H100/H200, memória DDR5 ECC de até 8TB e liquid cooling direto para chip, fornecendo plataforma confiável para IA, HPC e análise de dados avançada. A integração entre hardware, segurança e gerenciamento cria uma infraestrutura resiliente e escalável.
Considerações Finais
Para organizações que enfrentam demandas críticas de processamento paralelo, investir em um servidor 2U otimizado garante redução de riscos, eficiência operacional e competitividade. A configuração correta de CPUs, GPUs, memória e resfriamento é determinante para sucesso de longo prazo.
Perspectivas Futuras
À medida que modelos de IA e workloads HPC aumentam em complexidade, a necessidade de servidores com maior densidade e throughput continuará a crescer. Tecnologias como PCIe 6.0, GPUs de próxima geração e novas soluções de gerenciamento de energia e resfriamento serão fundamentais.
Próximos Passos Práticos
Empresas devem conduzir análise detalhada de workloads, mapear topologia de memória e GPU, implementar monitoramento contínuo e avaliar trade-offs entre densidade, performance e consumo energético antes de investir em infraestruturas de alto desempenho.

