Review supermicro GPU A+ Server AS -8125GS-TNMR2

Supermicro DP AMD 8U com AMD Instinct MI300X: desempenho máximo em IA e HPC
O Supermicro A+ Server AS-8125GS-TNMR2 representa uma das plataformas mais avançadas do portfólio de servidores GPU da linha Gold Series. Projetado em formato 8U, o sistema combina 8 GPUs AMD Instinct™ MI300X e processadores AMD EPYC™ 9004/9005 para atender às mais exigentes cargas de trabalho em Inteligência Artificial (IA), High Performance Computing (HPC) e automação industrial. Este artigo analisa em profundidade sua arquitetura, interconexões, eficiência térmica e benefícios estratégicos para empresas que buscam consolidar desempenho e densidade computacional extrema.

Contexto Estratégico e Relevância Empresarial
No cenário atual, empresas que dependem de modelos de IA generativa, análise de dados em tempo real e simulações complexas enfrentam o desafio de equilibrar poder computacional com eficiência energética e escalabilidade. A Supermicro, em parceria com a AMD, responde a esse desafio com o DP AMD 8U System with AMD Instinct™ MI300X 8-GPU, uma solução que redefine o padrão de densidade e conectividade em servidores GPU.
Mais do que potência bruta, esse sistema traz um ecossistema otimizado para interconexão direta GPU-GPU via AMD Infinity Fabric™ Link e suporte a até 6 TB de memória DDR5 ECC, fatores decisivos para cargas de trabalho de IA distribuída e HPC em escala de data center.
Problema Estratégico: Escalabilidade e Interconexão de GPUs
Os projetos de IA e HPC modernos exigem interconectividade eficiente entre múltiplas GPUs, o que determina diretamente a velocidade de treinamento de modelos e a largura de banda disponível para transferência de dados. Em arquiteturas tradicionais, limitações na comunicação entre GPUs e CPUs resultam em gargalos de desempenho e aumento de latência.
O AS-8125GS-TNMR2 endereça esse problema com um design otimizado para RDMA direto entre GPUs (GPU direct RDMA 1:1) e interconexão PCIe 5.0 x16 de alta velocidade entre CPUs e GPUs. Isso elimina intermediários desnecessários e maximiza a eficiência de comunicação, fator crítico para aplicações como deep learning, simulações de fluidos e inferência de modelos de larga escala.
Consequências da Inação: Gargalos, Consumo e Custo Operacional
A ausência de infraestrutura GPU otimizada, especialmente em cargas paralelas massivas, pode levar a um desperdício significativo de recursos computacionais. Sistemas baseados em PCIe 4.0, por exemplo, limitam a largura de banda entre GPUs, retardando o desempenho em até 40% em comparação com topologias baseadas em PCIe 5.0 e Infinity Fabric.
Além do impacto em desempenho, há implicações financeiras diretas: ciclos de treinamento mais longos aumentam custos energéticos e reduzem a eficiência por watt. Em ambientes de HPC, onde cada nó precisa entregar throughput previsível, a escolha de arquitetura torna-se um fator estratégico para o ROI do data center.
Fundamentos da Solução: Arquitetura de Desempenho Extremo
No núcleo da solução, o Supermicro A+ Server AS-8125GS-TNMR2 combina dois processadores AMD EPYC™ 9004/9005 com suporte a até 400W TDP e 8 GPUs AMD Instinct™ MI300X. Essa combinação é sustentada por um backplane PCIe 5.0 de baixa latência e topologia de interconexão que prioriza comunicação direta CPU-GPU e GPU-GPU.
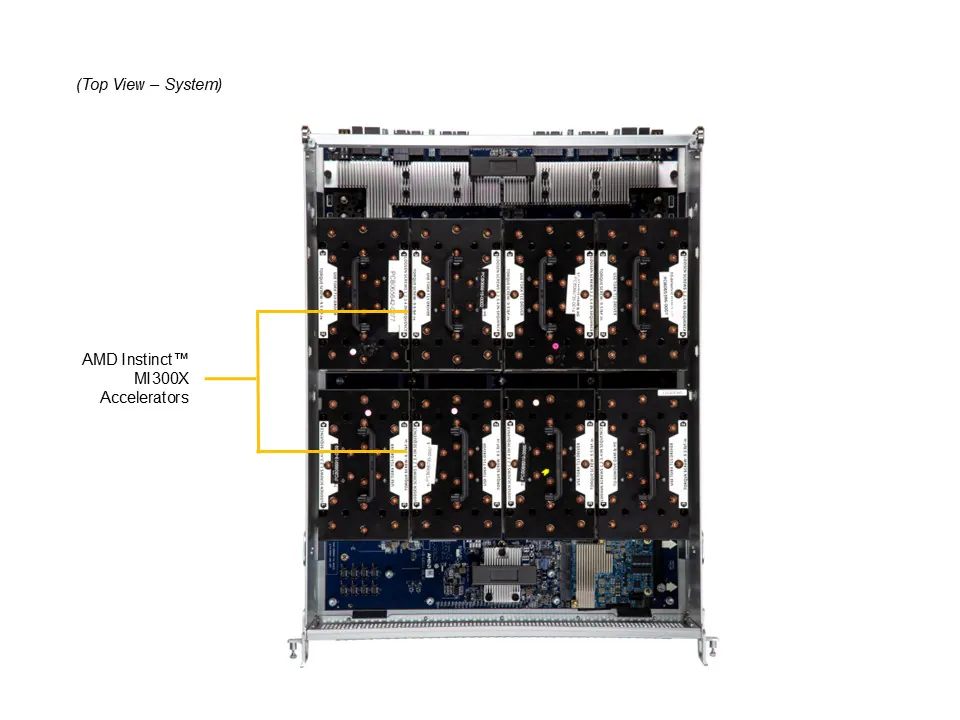
Memória e Largura de Banda
Com até 24 slots DIMM DDR5 ECC, o sistema oferece até 6 TB de memória com velocidades de até 6000 MT/s, permitindo fluxos massivos de dados em aplicações de IA distribuída. A integridade é garantida por suporte a ECC e a robusta arquitetura de energia com reguladores de 7+1 fases.
Armazenamento e Expansão
O servidor suporta até 16 baias NVMe hot-swap de 2,5″ (12 padrão + 4 opcionais), além de 2 baias SATA dedicadas e slots M.2 NVMe para o sistema operacional. Essa flexibilidade é crucial para workloads que exigem throughput de I/O constante e latência mínima.

Interconexão e Rede
Com 8 NICs dedicadas para RDMA direto entre GPUs e opções flexíveis de rede PCIe 5.0 x16 LP ou FHFL, o sistema garante conectividade de baixa latência com clusters externos e redes InfiniBand. Essa característica posiciona o modelo como um backbone ideal para clusters de IA ou HPC com comunicação peer-to-peer intensa.
Implementação Estratégica: Desempenho, Energia e Segurança
Projetar uma infraestrutura com 8 GPUs MI300X requer um equilíbrio cuidadoso entre potência térmica e estabilidade operacional. O AS-8125GS-TNMR2 utiliza um conjunto de 10 ventiladores industriais com controle automático de rotação e 6 fontes redundantes de 3000W com certificação Titanium (96%), assegurando operação contínua mesmo sob carga total.
Gestão e Orquestração
A camada de gerenciamento é um diferencial do sistema. Ferramentas como SuperCloud Composer®, Supermicro Server Manager (SSM) e SuperDoctor® 5 permitem supervisão granular de recursos, automação de updates via Supermicro Update Manager (SUM) e diagnóstico offline com Super Diagnostics Offline (SDO). O novo SuperServer Automation Assistant (SAA) amplia essa automação para escala de rack, ideal para data centers com centenas de nós GPU.
Segurança e Conformidade
O servidor implementa uma cadeia de confiança baseada em hardware com TPM 2.0 e Silicon Root of Trust (RoT), em conformidade com a norma NIST 800-193. Isso garante firmware autenticado criptograficamente, atualizações seguras e proteção em tempo de execução via System Lockdown e Remote Attestation. Essa abordagem de segurança é essencial em ambientes HPC e IA que processam dados sensíveis ou modelos proprietários.
Melhores Práticas Avançadas: Otimização e Governança
Para maximizar a eficiência do sistema, recomenda-se configurar o cluster em topologia híbrida CPU-GPU balanceada, assegurando a utilização plena das linhas PCIe 5.0. A integração com redes de alta largura de banda (100/200 GbE ou InfiniBand) potencializa o desempenho em pipelines de treinamento distribuído.
Do ponto de vista de governança, a infraestrutura deve incorporar políticas de firmware assinado e auditorias automáticas de integridade. O ecossistema Supermicro facilita isso com ferramentas de monitoramento contínuo e APIs abertas para integração com plataformas de observabilidade corporativas.
Medição de Sucesso: Indicadores de Eficiência e ROI
O sucesso da implementação deve ser medido por métricas como throughput de inferência por watt, tempo médio de treinamento e latência média GPU-GPU. Em benchmarks internos, sistemas baseados em PCIe 5.0 e MI300X demonstram ganhos substanciais em eficiência energética e densidade computacional por rack.
Empresas que migram de soluções de geração anterior podem observar reduções de até 25% em consumo energético e aumentos de até 40% na velocidade de inferência, refletindo diretamente em ROI operacional e competitividade em workloads de IA corporativa.
Conclusão: Estratégia e Futuro do Desempenho Escalável
O Supermicro A+ Server AS-8125GS-TNMR2 representa uma nova fronteira em design de servidores GPU para IA e HPC. Sua combinação de arquitetura AMD EPYC + MI300X, interconexões Infinity Fabric e gerenciamento avançado o posiciona como um dos sistemas mais completos do mercado em 2025.
Para organizações que buscam construir ou expandir data centers de IA, este servidor oferece o equilíbrio ideal entre potência, segurança e eficiência. À medida que a demanda por modelos maiores e inferência em tempo real cresce, arquiteturas como a deste 8U Supermicro se tornam o núcleo estratégico para a próxima geração de inovação computacional.

