Review Supermicro GPU A+ Server AS -4124GO-NART

4U GPU Server Supermicro com NVIDIA HGX A100: Performance Máxima para IA e HPC
O cenário atual de inteligência artificial (IA) e computação de alto desempenho (HPC) exige servidores que combinem escalabilidade massiva, throughput extremo e confiabilidade inquestionável. O 4U GPU Server Supermicro com NVIDIA HGX A100 8-GPU surge como uma solução estratégica para organizações que buscam executar cargas de trabalho críticas de deep learning, análise de dados em grande escala e simulações complexas, sem comprometer desempenho, segurança ou gerenciamento operacional.
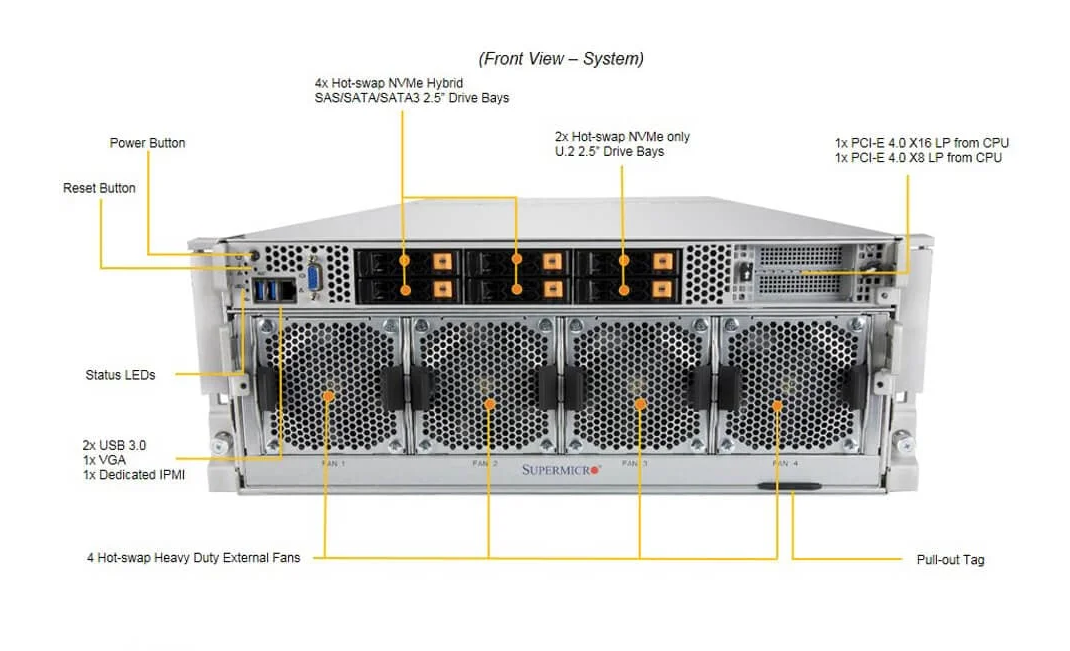
Contextualização Estratégica e Desafios Críticos
Com a evolução acelerada das demandas de IA generativa e modelagem de HPC, empresas enfrentam desafios como alta latência em processamento paralelo, limitações de memória GPU e riscos de downtime que podem comprometer projetos de pesquisa ou pipelines de produção. Sistemas convencionais não oferecem comunicação direta eficiente entre múltiplas GPUs, gerando gargalos de performance e desperdício de investimento em infraestrutura.
Além disso, a crescente complexidade regulatória em segurança de dados e governança exige que servidores corporativos suportem autenticação robusta, monitoramento ativo e resiliência de firmware, prevenindo vulnerabilidades que poderiam impactar dados sensíveis ou interromper operações críticas.
Consequências da Inação
Ignorar a atualização para uma infraestrutura GPU avançada implica custos ocultos significativos. Entre eles estão baixa eficiência computacional, maior consumo de energia devido a ciclos de processamento mais longos e risco de falhas críticas durante execuções simultâneas de modelos de deep learning. O tempo perdido em debugging e ajuste de software pode gerar atrasos em lançamentos de produtos, simulações científicas e análise de dados estratégicos.
Organizações que não adotam servidores com interconexão de alto desempenho entre GPUs, como o NVLINK v3.0 e NVSwitch da NVIDIA, perdem vantagens competitivas, pois não conseguem executar treinamentos de modelos em grande escala de forma otimizada, impactando a capacidade de inovação e tomada de decisão baseada em dados.
Fundamentos da Solução: Arquitetura do 4U GPU Server
O 4U GPU Server Supermicro integra até 8 GPUs NVIDIA HGX A100, com 40GB (HBM2) ou 80GB (HBM2e) por GPU, oferecendo largura de banda de memória massiva para cargas intensivas. A arquitetura NVLINK v3.0, combinada com NVSwitch, garante comunicação ponto a ponto entre GPUs com latência mínima, eliminando gargalos típicos de interconexão PCIe padrão.
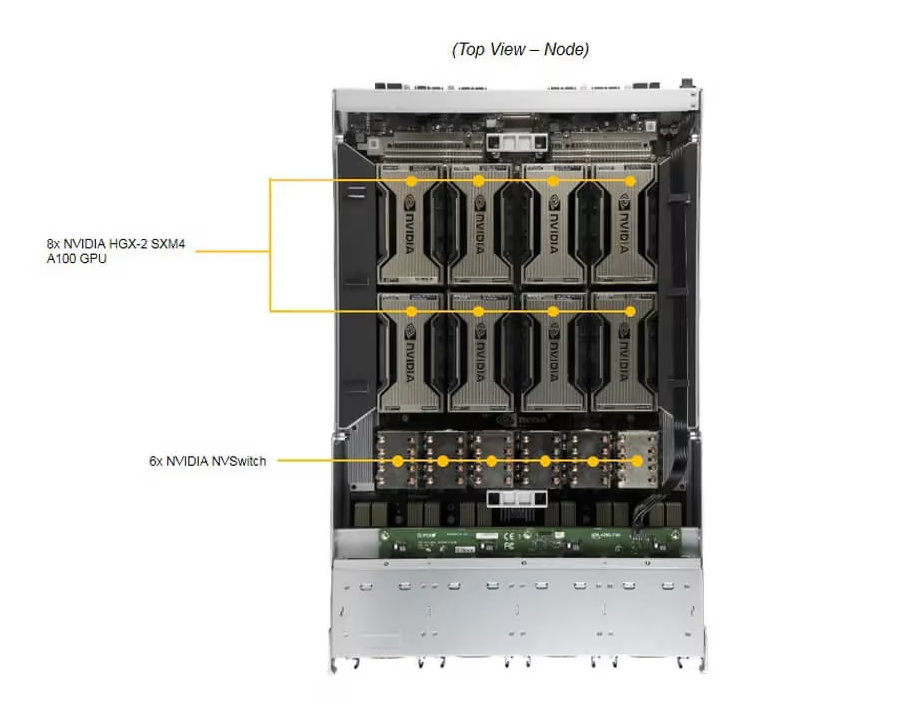
O servidor é alimentado por processadores duplos AMD EPYC™ 7003/7002, compatíveis com tecnologia AMD 3D V-Cache™, permitindo throughput massivo de dados entre CPU e GPU. A memória principal suporta até 8TB DDR4 Registered ECC 3200MHz, distribuída em 32 DIMMs, garantindo integridade e correção de erros em cargas críticas.
Expansão e Armazenamento NVMe
O sistema oferece 6 baías hot-swap de 2,5″ NVMe, com opção de expansão para 10 drives via 4 baías traseiras adicionais. A integração de PCIe 4.0 x16 e x8 via switch e CPUs assegura compatibilidade com controladores de alta velocidade e placas de expansão (AIOM), permitindo configurar ambientes de armazenamento flash de altíssima performance para dados temporários e modelos em treinamento.
Redes e Conectividade de Alto Desempenho
Para workloads que demandam GPUDirect RDMA, o servidor fornece NICs dedicadas em razão 1:1 com cada GPU, eliminando overhead de CPU e aumentando throughput de rede. Isso é crucial para clusters de deep learning distribuído, onde múltiplos nós compartilham modelos e datasets massivos em tempo real.
Implementação Estratégica e Considerações Operacionais
Implantar um servidor deste porte requer atenção aos detalhes de resfriamento e energia. O modelo 4U utiliza até 4 ventiladores hot-swap de 11.500 RPM e fontes redundantes de 2200W Platinum (3+1), garantindo operação contínua e mitigando risco de downtime. Considerações ambientais incluem operação entre 10°C e 35°C, com umidade relativa entre 8% e 90%, além de compliance RoHS.
O gerenciamento é facilitado via Supermicro Server Manager (SSM), Power Manager (SPM), Update Manager (SUM) e SuperDoctor® 5 (SD5), com suporte IPMI 2.0, KVM-over-LAN e monitoramento completo de saúde do sistema. Esse ecossistema de software permite operações proativas, automação de alertas e manutenção remota, reduzindo custo operacional e melhorando tempo de disponibilidade.
Segurança e Conformidade
A plataforma inclui Trusted Platform Module (TPM) 2.0, Silicon Root of Trust (RoT) conforme NIST 800-193, boot seguro e atualizações de firmware criptografadas. Essas funcionalidades mitigam riscos de intrusão, ataques a firmware e comprometimento de dados sensíveis, alinhando-se a políticas corporativas de governança e auditoria.
Melhores Práticas Avançadas
Para maximizar ROI, recomenda-se alinhar alocação de GPUs a workloads específicos, balanceando treinamento de IA, inferência e simulações HPC. O uso de NVMe para datasets temporários e cache de GPU minimiza latência, enquanto monitoramento contínuo de temperatura e performance permite ajustes dinâmicos de frequência e potência via Supermicro Power Manager.
Implementações em cluster podem explorar interconexões NVSwitch para compartilhamento eficiente de modelos e redução de overhead de comunicação, enquanto a segregação de tráfego de rede usando RDMA dedicada assegura throughput constante para pipelines críticos de dados.
Medição de Sucesso
Métricas-chave incluem throughput de treinamento (samples/s), utilização média da GPU, latência de interconexão NVLINK/NVSwitch e disponibilidade do sistema. Indicadores de saúde do hardware, como monitoramento de tensão, temperatura e velocidade de ventiladores, garantem operação contínua sem degradação de performance. Relatórios de energia e eficiência de resfriamento ajudam a otimizar custo total de propriedade (TCO).
Conclusão
O 4U GPU Server Supermicro com NVIDIA HGX A100 8-GPU representa a convergência ideal de desempenho extremo, confiabilidade e segurança para ambientes de HPC e IA. Ao integrar GPUs de alta capacidade, interconexão NVLINK/NVSwitch, processadores AMD EPYC de última geração e memória ECC de alta densidade, o servidor permite executar cargas críticas com máxima eficiência.
Organizações que adotam esta infraestrutura ganham vantagem competitiva em projetos de deep learning, simulações científicas e análise de grandes volumes de dados, mitigando riscos operacionais e garantindo compliance rigoroso. A flexibilidade de expansão, gerenciamento avançado e recursos de segurança tornam o 4U GPU Server uma escolha estratégica para ambientes corporativos e de pesquisa de ponta.
Perspectivas futuras incluem integração com orquestração de clusters HPC, escalabilidade horizontal em datacenters de IA e otimização contínua de energia e desempenho para atender às demandas crescentes de workloads massivos. O próximo passo prático envolve planejar a configuração do servidor conforme o perfil de uso, avaliando quantidade de GPUs, memória e armazenamento para máxima eficiência operacional.

